분산 처리 시스템
1. 분산처리 아키텍쳐가 도입된 역사 및 중요성
분산 처리 기술은 크게 분산 데이터 관리 기술, 분산 병렬 처리, 분산 파일 시스템 이 세 가지로 이루어져 있고, 사실 뗄 수 없는 관계지만 편의를 위해 분리해 설명한다.
2000년대 이후 웹 환경이 일반화되면서 대규모의 사용자 요청을 안정적으로 처리할 수 있는 기술인 EJB(Enterprise Java Bean) 등이 등장하였다. EJB는 이름에서처럼 자바 진영에서 나온 표준 분산 아키텍쳐이며, 사용자의 요청과 비즈니스 처리 등의 논리적인 아키텍쳐 구분을 물리적인 배포 단위로 구분할 수 있게 했다. 이와 함께 등장한 개념이 CBD(Component Based Development)와 SOA(Service Oriented Architecture)가 있는데, CBD는 서비스를 구성하는 단위를 논리적인 컴포넌트로 나누고 컴포넌트를 개발해 배치하는 방법으로 개발 방법론이고, SOA는 시스템의 아키텍쳐를 제시했다. 클라우드 컴퓨팅은 이러한 EJB, CBD와 SOA 등을 발전시켜 시스템의 내외부 연동을 표준화된 방법으로 기본 제공하며, 필요에 따라 쉽게 스케일 아웃이 확장 가능하게 구성한 시스템이라고 할 수 있다.
EJB같은 분산 환경이 장점이 많음에도 불구하고 분산 기술에 대한 성숙도와 능력이 낮았기 때문에 그 당시에는 큰 주목을 받지 않았으나 지금은 상황이 많이 바뀌었다. 현재 다양한 기술들이 오픈소스로 제공되며, 멀티프로그래밍 언어 지원, 분산 환경 제어 기술, 분산 스토리지 등 여러 분산기술이 일반화되었다.
2. 분산 데이터 관리 기술
분산 데이터 관리 시스템(DDM; distributed Data Management)은 대규모의 구조화 데이터를 분산되어 있는 환경에 저장하는 시스템으로, 기존의 관계형 데이터 관리 시스템(RDBMS; Relational Database Management System)은 데이터를 구조화하여 체계적으로 저장 및 관리가 가능하지만, 높은 확장성과 대규모 데이터를 처리하기엔 부족함이 있어, 여러 종류의Nosql(Not Only sql)류의 데이터 관리 시스템이 클라우드 데이터를 위한 기술로 활용되어지고 있다.
2.1 Nosql
Nosql은 전통적인 RDBMS의 형식을 따르지 않는 형태의 데이터 저장 기술이다. 데이터의 종류와 크기에 따라 많은 종류의 형태의 Nosql이 존재 하는데, 크게 key-value database, Document Database, BigTable Database, Graph Database 4가지로 분류한다. 많은 오픈 소스 Nosql DB들이 존재하고, 현재에도 계속해서 우위를 겨루며 발전하고 있다.
2.1.1 Key-Value DB
Dictionary나 hash의 아이디어로 만들어진 데이터베이스로, 가장 단순한 형태이다. 고유한 key값에 따른 매칭되는 value값을 저장하는 방식으로 이루어져 있으며, 그로 인해 value값을 통한 검색이 어렵다. 대표적으로 Redis, Riak, Voldemort, Memcached등이 존재한다.
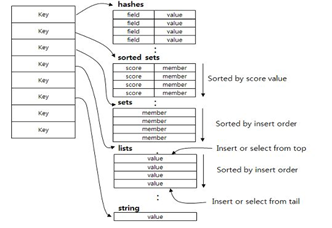
[그림 1] Redis의 기본 저장 구조 및 데이터 형식
Redis는 메모리 기반의 DB로, 굉장히 빠른 속도를 자랑한다. 이와 비슷한 Memcached가 있는데, Redis는 그보다 다양한 자료형과 데이터 저장시 메모리와 hdd를 같이 사용하기 때문에 shutdown되어도 데이터를 유지하는 장점이 있다. 저장 방법은 2가지 방법이 있는데 Snapshotting과 AOF(Append on file)의 두가지 방식이 있다. Snapshotting은 말 그대로, snapshot을 찍는 형태로 메모리에 있는 내용을 hdd에 저장하게 되는데, 체크포인트 이후의 데이터는 유실된다는 단점이 있지만 빠른 편이다. AOF는 연산을 모두 LOG에 기록하게 되는데, 그만큼 오버헤드가 발생하게 되고, restart 시간이 오래 걸린다. Redis의 구조는 master와 slave 그리고 fail-over를 처리하기 위한 Sentinel이 존재하는데 master는 Read/Write을 하고 slave는 Read만을 담당한다.
2.1.2 Document DB
key-value 모델보다 구조화된 DB이며, key에 해당하는 value 필드에 데이터를 저장하는 구조는 같으나, value가 document로 표현되며 JSON, XML과 같은 구조화 데이터 타입이어서 복잡하고 계층적인 데이터를 저장하기에 유용하다. 그러므로, 하나의 데이터가 여러 테이블에 나눠 저장될 필요가 없다. 대표적으로 MongoDB, Couchbase 등이 있다.
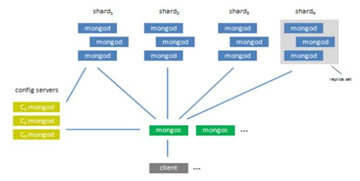
[그림 2] MongoDB 구조
MongoDB는 기본 단위로 Collection과 Document를 사용한다. Collection은 RDBMS의 Table과 유사하며, Document는 Collection에 들어가게 되는 하나의 객체로 이해하면 편하다. 내부의 구조는 [그림 2]에서와 같이 client가 transaction을 요청하면 mongos는 요청을 받아 설정 서버의 partition정보를 참고해 적절한 데이터 서버로 요청을 포워딩하게 된다. mongod는 데이터를 저장하고 관리를 하며, config server는 샤딩에 대한 환경 설정과 partitioning 에 대한 정보를 관리한다. MongoDB도 replication을 제공하며, slave mongod가 master mongod에 주기적으로 접근해 CRUD에 의한 변경사항을 적으면서 백업한다. 이 때 보통 1개의 primary와 2개의 secondary로 구성되는데, primary가 master역할을 하고, secondary가 slave 역할을 한다. primary가 제 기능을 못할 때, 보통 홀 수개로 구성한 환경에서 투표를 통해 뽑은 secondary를 primary의 oplog를 기반으로 복제되어 primary 역할을 해 fail over하게 된다.
2.1.3 BigTable DB
Column Family DB라고도 하며, key-value에서 확장된 형태로, 한 개의 key 내에 여러 column을 넣어, 새로운 데이터가 들어가도, 새로 열을 추가시키거나, 기존 데이터를 업데이트할 필요 없이 처리할 수 있는 DB로, 불필요한 NULL value를 추가할 필요가 없고, 유연하다. 하지만 join이 안되므로(다른 Nosql도 join은 어렵지만), 여러 테이블에 중복으로 관리하는 방법을 대신 사용한다. 대표적으로 Cassandra와 HBase가 존재한다.
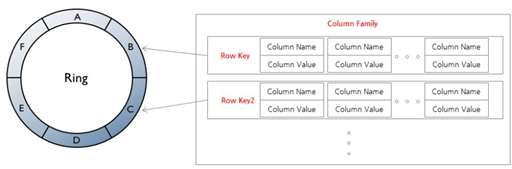
[그림 3]Cassandra의 기본 구조
Cassandra는 Facebook에 의해 2008년 Apach 오픈소스로 공개된 DB로, 대용량의 transaction에 비해 고성능 처리가 가능한 것이 장점이다. Cassandra는 ring 형태의 구조를 가지고 있으며, hashing을 통해 링에서 데이터를 노드별로 분산하여 저장한다. 이 때 data를 저장하기 위한 유일한 키를 partition key라고 하며, cluster key는 이 data layer에서 column을 정렬시키기 위한 key이다. 신기한 것은, Cassandra는 기본적으로 Consistent hashing과 gossip protocol을 사용하기 때문에 master 없이 동작한다. 또한, data node마다 범위가 다른 데이터의 복제본을 유지하여 replication을 처리해, 분산과 복구를 담당해서 하는 서버가 존재하지 않는다.
3. 분산 병렬 처리
분산 처리는 네트워크를 통해 물리적으로 연결되지 않은 컴퓨터가 어떤 일을 나누어 처리하는 것을 의미한다. 2004년, 구글은 MapReduce 병렬 처리 시스템을 발표했고, 발전을 거듭하여 현재 사실상 대규모 분산 처리 분야에서 표준 모델로 자리를 잡게 되었다.
3.1 MapReduce
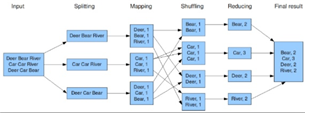
[그림 4]MapReduce의 기본 원리
[그림 4]의 MapReduce 과정을 설명하자면, input에 대해, 라인 단위로 split한뒤, Map함수를 통해 key-value형식으로 변환 과정이 이루어진다. shuffle을 통해 sorting과 partitioning이 이루어진 뒤 reducer를 통해 결과값을 도출해 합치는 과정이다. 이처럼, 분할시킨 input을 여러 컴퓨터가 나눠 처리할 수 있다는 점이 중요하다.
4. 분산 파일 시스템
분산 파일 시스템(DFS, Distribute File System)은 막대한 양의 데이터를 저장하고 관리하기 위해 수많은 서버들에 데이터를 나누어 저장하고 관리하는 파일 시스템이다. 분산 병렬 처리 프레임워크인 MapReduce와 함께 GFS(Google File System)를 지나 Hadoop 등으로 발전하였다.
4.1 GFS(Google File System)
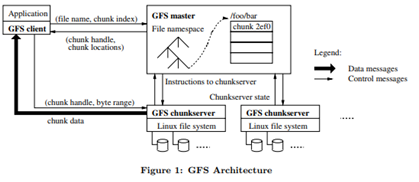
[그림 5]GFS의 기본 구조
GFS는 하나의 GFS master와 GFS chunckserver, GFS client로 이루어져있다. 이름과 같이 master는 전체를 관리하고 통제하며, chunckserver는 물리적인 서버로 실제 입출력 데이터를 처리한다. client는 chunkserver로부터 chunk data를 받아 입출력을 담당한다. 파일이 chunk 단위로 쪼개져 chunkserver로 저장되는데, 여러 개의 복제본도 chunkserver에 분산되어 저장되므로, 파일에 손상이 생길 경우 이를 이용해 복원한다. master의 상태 또한 여러 chunkserver에 저장되어 어느 서버가 고장나더라도 복구가 가능한 구조로 cluster architecture 구성에 큰 영향을 끼쳤다.
4.2 Hadoop
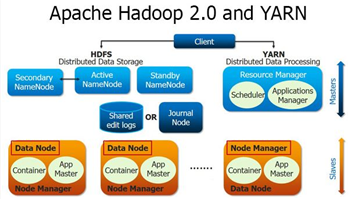
[그림 6]Hadoop 2.0의 기본 구조
Hadoop은 GFS를 대체하기 위해 자바로 구현된 오픈소스로, 초기에는 GFS와 큰 차이점이 없으나 Hadoop 2.0으로 version up되면서 더 큰 인기를 끌게 되었다. Yarn의 도입으로, Hadoop 1.0에서의 Job tracker의 역할을 Resouce Manager와 Application Master로 분리시키며 병목현상을 해결하였고, NameNode의 다중화를 통해 SPOF(Single Point of Failure)의 위험을 없앴다. 동작 방식은 Client의 명령에 대해 Resource Manager에게 전달이 되고, 자원 할당을 위해 scheduler에게 넘어간다. scheduler는 slaves중의 container 하나를 Application Master로 임명하고, 임명된 Application Master는 Resource Manager와 통신하여 Container를 요청하고, Node Manager에게 제공해 Container를 실행시킨다. Application Master는 실행 상태등에 대해 통신을 받으며 작업이 종료되면 Application Master는 등록을 해제하게 된다.
References
[1] Borko Furht, Armando Escalante, HANDBOOK OF CLOUDCOMPUTING, Boca Raton, FL: Springer, 2010, pp. 90-100.
[2] K. S. Kim, et al. 클라우드 컴퓨팅 설계 및 구현, 서울시 강북구, 인수동: 홍릉과학출판사, 2012, pp. 70-76.
[3] H. J. Kim, et al. 클라우드 컴퓨팅 구현 기술, 경기도 의왕시, 내손동: 에이콘출판주식회사, 2010, pp. 56-70.
[4] S. Ghemawat, H. Gobioff, and S. Leung, “The Google file system,” in Proc. 19th ACM Symp. Operating Syst. Principles, 2003, pp. 29–43
[5] D. H. Joe. “In memory dictionary Redis 소개.” Internet: https://bcho.tistory.com/654, Jan. 24, 2014.
[6] I. B. Kim. “Mongo db 2.x to 3.x.” Internet: https://www.slideshare.net/revolutionistK/mongo-db-2x-to-3x, Oct. 29, 2015.
[7] S. J. Um. “Apache Cassandra 톺아보기 – 1편.” Internet: https://meetup.toast.com/posts/58, Jan. 18, 2016
[8] Y. S. Kim. “하둡의 진화 YARN(Yet Another Resource Negotiator) #2.” Internet:https://blog.skcc.com/1884, Aug. 04, 2014.
[9] K. M. Kim. “하둡 맵리듀스(MapReduce) 알아보자.” Internet: https://jayzzz.tistory.com/44, Sep. 05, 2017.