Curiosity-driven Exploration by Self-supervised Prediction
1. Abstract
curiosity는 agent에게 intrinsic reward(중요)를 준다. 이는 environment를 explore하고, 미래의 유용할 skills를 배우게 한다. 이들은 curiosity를 agent가 action을 취했을 때, 이를 예측하도록하고 이 차이를 curiosity로 설정 했다. input이 pixel 단위로 들어오거나 그런경우는 예측이 의미없어지고 어려워지기 때문에, 관련없는 부분은 무시하게 만들었다.(feature space로 만들어버려서 high dimension을 해결했음) 크게 세가지 환경이 조사되었는데, 1) reward가 sparse할때, curiosity는 환경과 더 적은 interaction을 하게하고(– 정확한 내용은 뒤를 다읽고 다시풀어쓰겠음 –) 2) reward가 없을 때, 좀더 explore하도록 함 3) unseen scenarios에대한 generalization
Introduction
강화학습은 reward를 maximizing 하는데 초점을 두고있다. 하지만 많은 경우 이 reward가 sparse하다. 이에 접근하는 방법으로 이전의 exploration은 너무 우연에 치중했었다. 이런 주먹 구구식 exploration을 개선하기 위해 사람의 curiosity를 도입하게 되었는데,
사람에게 있어 curiosity는 novel state를 발견하는데 주로 설명된다. 강화학습에서도 intrinsic rewards는 extrinsic reward가 sparse할때도 큰 도움을 준다. 1) novel state를 찾도록 도와주고 2) agent가 action을 할 때, 일어날 상황에 대한 예측 오차를 줄여준다.
여기서 novelty 하다는 것을 measuring 하기위해 환경의 분포에 대한 확률 모델이 필요한데, input으로 high dimension이어서 어렵고 agent-environment system 이 stochastic하기 때문에 더어렵다.+ noisy. 그렇기 때문에 목적에 related하고, independant한 부분을 중요하게 다룬다. 또다른 제안으로는 hard to predict한 부분을 learnable하다고 정의할 수 있다. 그래도 이런 learnablity는 정의하기 어렵다.
위의 문제를 해결 하기 위해 sensory input을 feature space로 변환한다. 이러한 과정은 self-supervised 하게 진행한다.
2. Curiousity-Driven Exploration
agent는 2가지 subsystems로 구성된다. 하나는 intrinsic reward generator, 다른 하나는 일련의 actions를 만들어 reward signal을 maximize하는 policy이다. intrinsic curiosity 는 시간 \(t\) 에 따른 intrinsic reward \(r^i_t\) 와 extrinsic reward \(r^e_t\) 로 이루어진다. 앞의 policy sub system은 \(r_t = r^i_t + r^e_t\) 로 학습이 된다.
policy는 \(\pi(s_t;\theta _ P)\) 로 표현했고, \(\theta _P\) 는 neural network의 parameters이다. agent는 주어진 state \(s_t\) 에 대해, policy에 의해 sample 된 action \(a_t ~ \pi(s_t; \theta _P)\) 를 수행한다. \(\theta _P\) 는 다음의 식에 의해 optimize 된다.
\[max_{\theta _{P}} \mathbb{E}_{\pi(s_t;\theta_P)}[\sum_t {r_t}]\]curiosity는 다방면의 policy에 쓰일 수 있으나, 여기선 A3C를 이용해 experiments를 냈다.
2.1 Prediction error as curiosity reward
바람에 흔들리는 나뭇잎을 생각해보았을 때, 바람을 모델링하기에는 무리가 있고 계속해서 curiosity가 높게 나타날 것이다. 그래서 계속해서 exploration 을 하게 될 수 있다. tabular form에서는 온 횟수를 기록하는 것도 이런 issue를 겪었기 때문이다. Measuring learning progress를 prediction error 대신 사용한 방법도 제안되었지만 현재 그것을 computationally feasible 하게 계산할 mechanism이 없다.
그러면 무엇이 curiosity curiosity를 measure하기 위한 좋은 방법일까?
이 질문에 대답하기 위해 agent’s observation을 3가지 cases로 나누었다.
- (1) agent에 의해 controlled 되는 것
- (2) agent가 controll 할 순 없지만 agent에게 영향을 주는 것
- (3) agent가 controll 할 수도 없고, 영향도 끼치지 않는 것
여기서 feature space는 (1)과 (2)를 잘 반영해야되고 (3)은 지양해야한다.
figure.2는 뒤에서 설명할 예정이다.
2.2 Self-supervised prediction for exploration
모든 상황에 대해 hand designing된 feature representation대신에, 여기에서의 목표는 general mechanism이다. 그렇기 때문에 두개의 sub-module을 제안 했고, 첫 번째 sub-module은 raw state \((s_t)\) 를 feature vector \(\phi(s_t)\) 로 바꿔주고 두 번째 모듈은 encoding된 state인 feature \(\phi(s_t), \phi(s_{t+1})\) 를 받아 state \(s_t -> s_{t+1}\) 로 move 시킬 action \((a_t)\)를 predict한다.
(\(s_{t+1}\) 를 인퍼런스하기 위해선 \(a_t\) 가 먼저 필요한게 당연한거아님? 이라고 생각할 수 있는데 a_t를 추정하는 policy network는 따로 있다. 궁금증을 참고 좀 더 보자)
learning function으로 \(g\) 는 다음과 같이 정의 된다.
\[\hat {a_t} = g(s_t,s_{t+1};\theta_I) (2)\]\(\hat {a_t}\) 는 action \(a_t\)의 추정이고, neural network parameter \(\theta_I L_I(\hat{a_t},a_t)\) 는 다음과 같이 optimize된다.
\[\min_{\theta_I}{L_I(\hat{a_t},a_t)} (3)\]만약 \(a_t\) 가 discrete하다면 soft-max로 최대 우도 추정으로 구한다.( KL-divergence로 구할 수 있다.)
여기선 추가적으로, inverse dynamics model로 feature encoding을 predict하는 network를 하나 더만들었다. f는 model의 forwarding이다.
\[\hat {\phi}(s_{t+1}) = f(\phi(s_t),a_t; \theta_F) (4)\]그리고 loss는 다음과 같이 구성하였다.
\[L_F(\phi(s_t),\hat{\phi}(s_{t+1})) = \frac {1}{2} || \hat{\phi}(s_{t+1}) - \phi(s_{t+1}) ||^2_2 (5)\]intrinsic reward는 다음과 같이 계산된다.
\[r^i_t = \frac {\eta} {2} ||\hat{\phi}(s_{t+1}) - \phi(s_{t+1}) ||^2_2\]그리고 (3)과 (5)를 각각 optimize 했다. inverse model(은 계속해서 나오지만 (2)의 action을 예측하는 네트워크이다.)는 agent’s action을 predicting하면서 predict 하는데 relevant한 feature map을 만들게 되고, 이러한 구조를 여기서는 Intrinsic Curiousity Module(ICM) 이라고 한다. 그래서 robust하고 전체적인 loss는 이렇게 정의할 수 있다.
\[min_{\theta_P, \theta_I, \theta_F} [-\lambda \mathbb{E}_{\pi(s_t;\theta_P)}[\sum_t{r_t}] + (1 - \beta)L_I+\beta L_F]\]이제 대략적으로 잡힌 개념을 가지고 그림을 통해 확실하게 이해하자면,
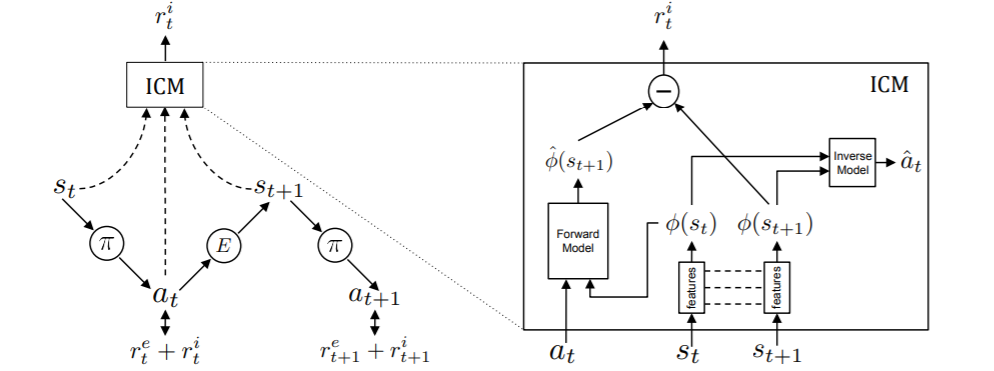
현재의 state \(s_t\)를 가지고 policy \(\pi\) 는 action \(a_t\) 를 인퍼런스하게 되고, 이를 통해 \(s_{t+1}\) 를 얻게된다. 이를 가지고 ICM에 넣게 되는데, \(a_t , \phi(s_t)\) 를 통해 다음 encoded state \(\phi(s_{t+1})\) 를 얻은 것과, \(\phi(s_t), \phi(s_{t+1})\) 를 통해 \(\hat {a_t}\) 를 인퍼런스하는 훈련을 한 inverse model의 네트워크를 통해 loss를 구한다. 정리하면 ICM엔 3개의 모델이 있는데 state encoding 모델, forward model, inverse model이다. 이를 통해 \(r^i_t\) 를 구하게 되고, (그러면 inverse model은 왜쓰냐 할 수 있겠지만, inverse model은 말했듯이, action에 영향을 주는 state만 정확하게 mapping 할 수 있도록 돕는다. 그리고 그 predicted action은 loss로만 쓰이고 버려진다. )