Discrete Sequential Prediction of Continuous Actions for Deep RL
Abstract
고차원의 continuous action space를 가질때, 그걸 discrete하게 쪼개서 푸는 문제에 대해 효과적으로 해결하기 어려웠으나, 이 논문에서는 sequence-to-sequence 모델에 영감을 받아, high dimension problem을 한 dimension씩 output을 내는 식으로 해결하였습니다. 특히 어떻게 Q-value와 policy를 어떻게 modeling하는지에 대해 설명하였습니다. 이런식으로 모델링을 하면, 결합된 action space에 대해 해결할 수 있습니다.
Introduction
continuous action space는 DP도 적용하기 어렵고, 본질적으로 특정 function을 maximizing하기 어려운 특성이 있기 때문에, 이를 이 논문에서는 large scale discrete action space로 해결하려 했습니다. 이 때, 이전에는 large action space를 chain rule을 이용해, hierarchy하게 만들었다는게 특징입니다. 이 논문에서는 Q-value를 이전의 joint action를 bellman operator를 사용한 일련의 조건부 value로 만들었습니다.
Method
2.2 Sequential DQN
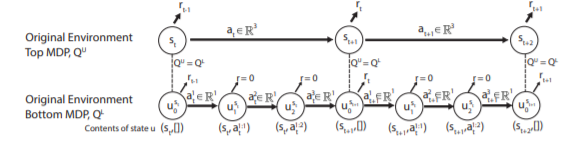 Sequential DQN(SDQN)은 MDP를 두 개의 upper layer와 lower layer로 구분했는데, upper layer는 실제 environment와 interaction하고, lower layer는 upper layer에 의해 transformed 된 MDP를 받습니다.
Sequential DQN(SDQN)은 MDP를 두 개의 upper layer와 lower layer로 구분했는데, upper layer는 실제 environment와 interaction하고, lower layer는 upper layer에 의해 transformed 된 MDP를 받습니다.
우리는 이렇게 MDP를 변형함으로써 N-D action 을 sequence of N 1-D action으로 변형 가능합니다. 이 때, 새로운 MDP는 두가지 룰에 의해 정의됩니다. 모든 1-D actions이 실행되어야 다음 new state이 나오고, 그전엔 zero reward를 받습니다.
이젠 1-D output space를 Q-learning에 직접 적용할 수 있습니다. 이는 mixture gaussian을 이용해 continuous action space에서도 적용가능합니다. 이 transformation의 단점은 이 transformed MDP를 풀기 위해, 더 많은 step이 필요하다는 것입니다. 이는 overestimation과 stability issue를 일으킬 수 있습니다. 하지만 이는 Q value를 lower layer와 upper layer를 동시에 시킴으로써 완화합니다.(Q-value가 같아야하는 s_u 지점에서) 이는 다음과 같이 표현할 수 있습니다.
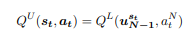
upper layer의 Q Network는 다음과 같이 TD-0 learning 을 합니다.
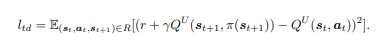
그다음, Lower layer의 Q Network도 Q-learning을 통해 update하는데, inner action sequence의 loss를 모두 구해야 합니다. 현재 action에 의한 q-value와 다음 step에서의 max q-value의 mse를 loss term으로 가져갑니다. 수식은 다음과 같습니다.
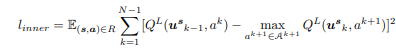
마지막으로, lower layer의 선택된 action들의 q-value와 upper layer의 q-value을 mse로 loss로 가져갑니다.
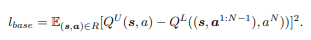
여기서는 double DQN을 사용해 stability를 높였습니다. 그리고, 이 모델을 Policy로 사용할 때도, argmax를 통해 action을 선택하였습니다.
2.3 Neural network parameterization
lower q network는 두 가지로 만들어 사용했습니다. 첫째로 LSTM을 사용했고, lower MDP는 action dimension이 다 다를 수 있기 때문에, feed forward neural network로 구성했고, 모든 이전의 action selection을 input으로 받았습니다. 그리고 찾아낸 점은 이 seperation이 좀더 stable하다는 점 이었습니다.
D : prob SDQN
다 설명해놓고 그냥 inner layer의 loss를 그냥 합해서 upper layer와 mse를 loss로 삼는 Add SDQN을 설명합니다.