Learn What Not to Learn : Action Elimination with Deep Reinforcement Learning
Abstract
많은 가능한 action이 주어졌을 때, 어떻게 행동을 해야하는지는 RL에서 큰 이슈입니다. 특히 그 action들이 서로 연관이 없을때 말이죠. 이런 경우, 어떤 상황에서 우리는 어떤행동을 하지 말아야 한다고 배움으로써 좀 더 쉽게 해결할 수 있습니다. 그래서 이 논문에서는 Action-Elimination Deep Q Network를 제시하는데, 이는 sub-optimal을 만드는 action을 제거해버리는 Action Elimination Network(AEN)와 RL의 결합으로 만들어집니다. AEN은 invalid action을 추론하도록 만들어지고, supervised learning을 통해 이루어집니다. 이를 통해 1000개 이상의 discrete action space에서 vanilla DQN보다 빠르게 학습하고, generalized되었습니다.
1.Introduction
state space와 action space가 큰 경우, Control policy를 학습시키는 것은 RL에서 실제 문제에 적용시키기 어려운 치명적인 문제입니다. 문제의 크기가 증가할 수록, 그에 따른 연산량이 지수적으로 증가하기 때문입니다. 이를 차원의 저주라고 합니다. Deep Reinforcement Learning(DRL)에서는 Deep Neural Network(DNN)를 활용해 value function과 policy를 근사하면서, 이 문제를 해결하려하는데, 이는 어떠한 도메인 지식없이 agent를 generalize하는 능력이 좋기 때문입니다.
이러한 DRL의 큰 성공에도 불구하고 실제 세상에서는 적용이 어려운 상황입니다. 이 문제중 하나는 많은 문제들의 목표가 large action space에서의 해결이기 때문입니다. 사람들은 관련없거나 불필요한 action을 잘 거르고 가능한 action에 있어서만 주어진 상황에대해 대처하는데 RL agent는 그런 action에 대한 insight가 없기 때문에 computation에서의 큰 낭비가 생기는 것입니다.
traffic control, power grids, natural language domain에서 주로 large action space에 sequential decision-making 문제를 생각해 볼 수 있습니다. RL은 많은 도메인에서 적용이 되었으나 function approximation과 exploration 두가지에 문제에 직면해 있습니다. 하지만 많은 이전의 연구는 단순히 large action space를 어떻게 다루느냐에 대한 연구만 많이 되었습니다.
이 연구에서는 이런 large action space에서에 대해 action elimination을 하는 방법을 다룹니다. 그 방법은 elimination signal을 이용해 action을 elimination하는 것인데, 이는 auxiliary reward라고 생각하면 편합니다. 즉 reward와 같은 environment로 받는 피드백입니다. 이는 environment가 이 action이 optimal인지를 feedback주는 형식인데, 많은 도메인에서 이는 rule-base로 생성 가능합니다. 예를들면 parser based 게임을 한다면, parser는 유효하지 않은 action에 대해 바로 feedback을 줄 수 있습니다. “나무를 올라라“ 라는 명령어를 넣었을 때 parser는 “오를 수 있는 나무가 없습니다” 같은. 이러한 signal은 supervised learning을 통해 예측할 수 있고, generalize할 수 있습니다. 그렇기 때문에 이 논문에서 주요하게 가정하는 것은, 이러한 elimination signal을 통해 어떤 action이 유효하지 않거나 별로 좋지 않다를 바로 피드백 받는 것은 Q를 모든 state-action pair에 대해 학습시키는 것 보다 낫다는 점 입니다.
좀 더 자세히 말하자면, Q function을 근사하는 것을 배움과 동시에 action을 eliminate하는 것을 배우는 시스템을 제시합니다. 여기서는 뒤에 설명할 모델을 위에서 간략히 말했던 natural language에서의 문제에 집중합니다.
여기서 DRL의 구조는 두개의 Deep Neural Network(DNN)을 사용하는데, DQN과 AEN으로 이루어져 있고, 이 네트워크들은 convolutional layer로 구성이 되어 있습니다. AEN의 마지막 activation으로는 linear contextual bandit model을 사용했는데 이는 관련없는 action을 높은확률로 제거하고, exploration과 exploitation을 균형있게 하도록 하여 유효한 action에 대해서만 Q-value를 학습하도록 합니다.
2. Related Work
Text-Based Game(TBG)
- Text base game은 NLP등과 결합되어 새로운 문제에 대한 지평을 열었습니다. text를 기반으로 하기 때문에 굉장히 큰 action space를 가지고 있고, 이전에 어떤 행동을 했는지에 관해 sequential하게 게임이 이어집니다. 또한, environment도 stochastic함을 담고있는데, 이러한 문제점이 agent를 수렴하기 어렵게 만듭니다.
Representations for TBG
- Text를 어떤식으로 나타낼 것인지에 대해 word를 embedding하는 식의 방법을 제시합니다. 2014년엔 word level에서의 shallow한 cnn을 구성하여 SOTA를 달성하였습니다.이외에도 다양한 방법이 있으나 NLP에서의 적용이 중점이 아니므로 넘어갑니다.
DRL with linear function approximation
- linear function의 stable에 대해 설명하고, model에 마지막에 linear하게 붙여주는게 자연스럽게 dynamics도 배우고, 위의 장점(feature engineering process의 필요성 + linear representation의 장점)을 합칠 수 있는 방법이라고 설명합니다.
RL in Large Action Space
- 이전에는 large action space에 대해 binary subspace로 바꾸거나, continuous action을 구해 embedding된 action space와의 nearest discrete action을 얻는 식으로 large action space를 해결했습니다. 하지만 이 연구는 사실 적은 action space를 쪼개서 낸 결과이기 때문에 한계가 있습니다.
또한 이러한 action elimination에 대해 연구된 역사로는 value function의 신뢰구간을 구하고 이를 이용해 optimal이 아닐 확률이 높을 action을 elimination하는 방식부터 해서, 위험한 state를 피하는 것을 agent가 까먹어버리는 것을 피하기 위해 위험한 상황인지에 대해 classifier를 만들어 agent에게 reward 형식으로 주었습니다. 또 affordances(현 상황에 가능한 행동들의 집합)를 inner product를 통해 얻는 방법도 있었습니다.
3.Action Elimination
이 섹션에서는 MDP에서의 elimination signal에 대한 설명을 합니다. 기본적인 RL에 대한 notation을 다루고, Q-learning에 대해 언급합니다. 여기서 중요한 점은 agent는 binary elimination signal e(s,a)를 받는데, 이게 1이면, state s 에서 action a는 eliminate됩니다.(실제 알고리즘내에선 threshold를 사용합니다) 다음부터 이 action은 state s 에서 뽑히지 않는다는 말입니다. 이 signal은 agent가 state s 에서 가지지 말아야 할 action에 대한 결정을 내리는데 도움을 주게 됩니다.
Definition 1.
- Valid state-action pairs는 elimination process에서 지우지 말아야할 state action pair를 말합니다.
시작전에 첫 유효한 state-action pairs에는 모든 state-action pairs가 들어있습니다.
Definition 2.
- 가능한 state-action pair는 elimination algorithm에 의해 제거되지 않는 state action pair입니다.
3.1 Advantages in action elimination
large action space에서 극복해야 하는 메인 문제들은 다음과 같습니다.
- Function Approximation
- Q-function이 large action space를 가질 때, sub-optimal로 수렴할 수 있는 문제는 잘 알려진 문제입니다. 오직 유효한 action에 대해서만 q 값을 측정하므로 overestimation에 대한 error를 줄여 Action elimination을 통해 그 문제를 완화시킬 수 있습니다. 유효하지 않는 action에 대해 q-estimation을 가지지 않는 것에 대한 당위성을 두가지 말하는데, 첫째로 유효하지 않는 sample을 sampling하는 것은 수렴에 도움을 주지 않기 때문에 필요하지 않다고 하였고, 둘째로, function approximation이 좀 더 단순해져서 수렴이 빨라진다는 점 장점으로 들었습니다.
- Sample Complexity
- 둘째로, Sample Complexity 문제에 관해서는 이를 학습량으로 보통 측정하게 됩니다.
- eliminate 되어야하는 A’ action set를 가져 epsilon greedy인 상태를 가정합니다.( value는 V*(s) - epsilon의 하한을 가짐)
- Optimal이 되기 위해선 1-delta의 확률로 최소
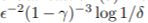 개의 sample이 필요합니다.(Lattimore and Hutter,2012)
개의 sample이 필요합니다.(Lattimore and Hutter,2012) - 만약에 eliminated action이 아무 reward를 발생시키지 않고, state가 변하지 않게한다면, 1 - gamma 만큼의 optimal value function과의 차이가 나게 만듭니다. 이는
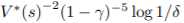 개의 wasted sample를 의미하고, gamma가 클수록 이 오차는 커지게 됩니다.
개의 wasted sample를 의미하고, gamma가 클수록 이 오차는 커지게 됩니다.
- 둘째로, Sample Complexity 문제에 관해서는 이를 학습량으로 보통 측정하게 됩니다.
elimination signal을 MDP로 embedding하는 것은 쉬운 일이 아닙니다. 첫번째로 이를 적용하는 방법은, reward shaping입니다. 실제 잘못된 action을 했을 때, reward를 감소시키는 방식으로 이를 해결할 수 있습니다. 하지만 이는 조정하기 위한 많은 테크닉이 필요합니다. 수렴 속도가 느려질 수도 있고, 가장 중요한건 sample efficiency를 줄일 수는 없습니다. 그래서 두번째로 policy가 두가지 역할을 수행하도록 할 수 있습니다.expected reward sum을 증가시키고, elimination signal error을 감소시키는 방향으로 말이죠. 하지만 이 두가지를 결합하는 것의 문제는 두가지가 dependency가 생겨 하나의 모델이 먼저 수렴해버리면 최적으로 수렴할 수 없는 문제가 있습니다. 그렇기 때문에, 여기서는 이 두가지를 contextual multi-armed bandits을 사용해 분리합니다. 이 contextual bandit은 state를 elimination signal로 변환하는 과정을 배웁니다. 아래에서는 먼저 linear한 contextual bandit의 theoretical result를 보고, 이후 Q-learning에서도 사용할 수 있음을 보입니다.
3.2 Action elimination with contextual bandits
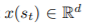 : state s_t를 embedding하는 function x 를 통해 변환된 값입니다.
: state s_t를 embedding하는 function x 를 통해 변환된 값입니다.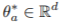 : 어느 parameter set이 존재할 때, elimination signal은 다음과 같이 표현할 수 있습니다.
: 어느 parameter set이 존재할 때, elimination signal은 다음과 같이 표현할 수 있습니다.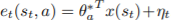 eta는 R-subgaussian성질을 띈, additive noise입니다.(subgaussian은 gaussian에서 bound해서 short tail을가지고 중앙에 더 밀집하게된 gaussian으로 이해하시면 편합니다.)
eta는 R-subgaussian성질을 띈, additive noise입니다.(subgaussian은 gaussian에서 bound해서 short tail을가지고 중앙에 더 밀집하게된 gaussian으로 이해하시면 편합니다.)- 그리고 elimination signal을 통해 binary하게 eliminate할지 말지에 대해 3. section에서 말한 것 처럼 threshold를 사용합니다.
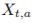 는 그 rows가 action a 가 선택되었을 때의 state representation으로 이루어진 matrix를 나타냅니다.
는 그 rows가 action a 가 선택되었을 때의 state representation으로 이루어진 matrix를 나타냅니다.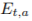 는 요소들이 elimination signal을 가리키는 vector입니다.
는 요소들이 elimination signal을 가리키는 vector입니다.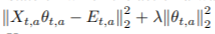 의 식이 objective function인데, 두번째 term은 regularization 식 입니다. 첫번째 term은 실제 elimination signal과 예측값의 차이를 나타냅니다.
의 식이 objective function인데, 두번째 term은 regularization 식 입니다. 첫번째 term은 실제 elimination signal과 예측값의 차이를 나타냅니다.
 은 regularization이 있는 Linear regression에서의 weights를 구하는 식입니다.
은 regularization이 있는 Linear regression에서의 weights를 구하는 식입니다.
정리중########################################################################### Theorem 2 에 의하면 (수식 전개 조금 더 정리 필요할듯) #################################################################################
결국, Action elimination의 과정이 linear를 가정했을 때, 1 - delta의 확률로 valid action을 지우지 않는 것을 보였습니다. 하지만 강조하는 점은, elimination signal의 기댓값이 linear할 때만을 얘기합니다. 또한 threshold를 어떻게 정하냐가 관건인데, 저자는 0.5정도면 적당하다고 주장합니다.
3.3 Concurrent Learning
지금까진 Q-learning과 contextual bandit algorithm이 동시에 배울 수 있는 것임을 보였습니다. 이번 챕터에서 해결할 문제는 두 모델이 서로 state-action distribution에 영향을 주는 것을 어떻게 해결하는지 입니다. Definition 3. Action Elimination Q-learning은 오직 허용가능한 state-action pair에 대해 학습하며, 허용가능한 action중에 가장 최고의 action만을 골라 act하는 알고리즘입니다.
만약 elimination이 끝나면, AE DQN이 수렴했다는 말입니다.
Proposition 1.
- state-action pair들이 eliminated되지 않는다면, 계속 방문될 것입니다. 그러므로, 1 - delta의 확률로 optimal에 수렴할 수 있습니다. 추가하자면 action은 최대
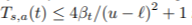 회 탐험해야 됩니다.
회 탐험해야 됩니다.
elimination signal에 noise가없다면, invalid action에 대해 항상 정확하게 제거해 invalid action은 유한번의 횟수만 sampling될 것입니다.
4. Method
Neural Net 연산은 gradient 연산을 통해 계속 parameter가 변화하게 됩니다.그렇기 때문에, Section 3에서 정의했던 phi가 고정되있지 않게 된 상황입니다. 이를 이 논문에서는 batch-update를 통해 해결합니다. target AEN을 정해놓고 각각의 몇 스텝마다 동기화를 해주는 것입니다.
 알고리즘을 살펴보면,
알고리즘을 살펴보면,
- Q : Q network
- Q^- : Target Q network
- E : AEN Network
- E^- : Target AEN Network
- phi : E에서 linear activation을 거쳐 만들어짐(V)
- e : theta * phi로 이뤄지는데 theta가 linear activation의 weight 라고 판단함
6. Summary
이 논문에서 AE-DQN을 살펴보았고, 일단 skip했지만, Zork라는 text base game에서의 실험을 진행하였습니다. action space가 계속 감소하면서 exploration이 효과적으로 진행되었고, linear contextual bandits을 사용해 수렴에 대한 보장을 증명하였습니다.