Off-policy multi-step Q-learning에 대해 원하는 step(lambda)만큼의 output을 가져 multi-step q-learning을 할 수 있는 방법이 있네요 :) 물론 world model을 통해 multi-step q learning이 가능한 방법도 있구요
objective
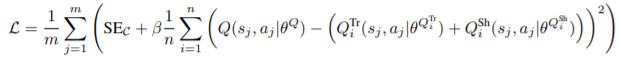
###SE
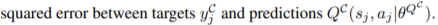
y^C_j
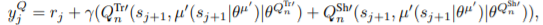
Q^Tr

Q^Sh
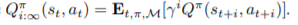
Architecture

결국 network architecture도 다음과 같이 짜야해서 조금 귀찮음을 느꼈지만, 충분히 reasonable했고, 설명도 적절했다고 생각합니다.