0. Abstract
Sparse reward은 RL에서 직면한 큰 문제중 하나입니다. 이 논문에서는 이를 해결하기 위해 Hindsight Experience Replay(HER)라는 technic을 소개합니다. 이 technic은 sparse하거나 binary한 reward definition에서 효과적인데 off-policy algorithm과 결합해 사용할 수 있습니다. 이 논문에서는 주로 로봇팔에대한 experiments들로 실험 결과를 보였으며, 이전엔 해결이 잘 안되던 문제들을 해결하는 성과를 보였습니다.
1. Introduction
이 논문의 key idea는 간단합니다.
model-free RL의 학습은 사람의 학습과 많은 다른 점이 있겠지만, 그중에서 이 논문이 주목한 차이점은 사람은 optimal이 아니었던 행동에 대해서도 배울 수 있다는 점입니다. 예로, 만약 사람이 하키를 한다면, 퍽(puck)을 골대로 날렸을 때, 퍽이 골대를 빗나가더라도 사람은 그 실패한 사실에서 어떻게 행동해야겠다는 것을 배울 수 있습니다. 하지만 강화 학습에서는 (골대 거리와의 차이 등등)이런 점이 reward로 세세하게 정해지지 않는다면 Agent는 그 행동에 대해 적절한 피드백을 받을 수 없습니다.
그렇기 때문에 여기서는 여러 goal을 만들어 이용하는 방식을 사용하는데, 이해를 위해서 Universal Value Function Approximators에 대한 얘기로 넘어가겠습니다.
2. Background
2.4 Universal Value Function Approximators(UVFA)
UVFA는 DQN에서 multi goal을 가질 때, 이를 해결하기 위해 사용된 DQN의 extension입니다. state마다 goal이 pair로 되어있어 sample됩니다. 그 다음, episode끝까지, 이 goal이 고정되어, agent는 그 goal에 맞는 reward를 받게 됩니다. 이는 DQN를 넘어 DDPG까지 충분히 확장 가능한 개념입니다.
3. Hindsight Experience Replay
3.1 A motivating example
한 쉬운 예를 들고 오겠습니다. State space은 n-dimension의 binary space이고,({0,1}^n) action은 그에 대응한 {0,…,n-1}의 action space를 가지고 있습니다. 이 때, goal의 n자리 배열에 대해 action은 state의 i-dimension을 filp할 수 있고, state가 마지막 action후에 이 goal과 같아야지만 positive reward를 받고 이외에는 negative reward를 받습니다. 그렇기 때문에 reward가 굉장히 sparse하다는 것을 직관적으로 이해하실 수 있을 것입니다. 일반 DQN은 여기서 13개 이하일때만 잘 풀어냈는데, HER을 적용시킨 DQN은 50개가 될때까지 푸는 능력을 가질 만큼 성능이 좋았습니다.
3.2 Multi-goal RL
2.4에서 관심가졌던 것처럼 이 논문에서는 multiple goal을 이용해 해결하고 싶어합니다. 그렇기 때문에, UVFA의 접근방식으로 부터 시작했고, policy와 value function의 input을 state뿐만아닌, goal을 넣어주게 됩니다. 하지만 이를 그대로 사용하기에는 여전히 reward function이 sparse하고 informative하지 않습니다. 그렇기 때문에, HER이라는 접근법을 사용하게 됩니다.
3.3 Algorithm
HER의 기본 알고리즘은 episode를 replay buffer에 저장하기 전에, original goal에 대해서만 저장하는 것이 아닌, 다른 goals에 대해서도 저장을 합니다. 이는 environment의 dynamics에 전혀 영향을 끼치지 않기때문에 쉽게 off-policy algorithm과 결합되어 사용될 수 있다는 장점이 있습니다. 이를 하나의 goal을 그저 좀 더 어렵게 내부적으로 학습시키는 학습 방법으로 볼 수 있으나, 실험적인 면에서 더 좋은 성능을 보이는 것을 보였습니다.
Algorithm

4. Experiments
4.2 Does HER improve performance?
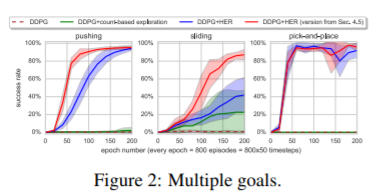
4.3 Does HER improve performance even if there is only one goal we care about?
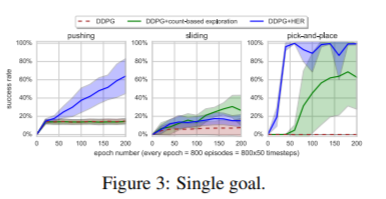
4.4 How does HER interact with reward shaping?
이 section에서는 reward shaping을 한 HER에 대해 실험했는데,
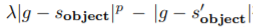 DDPG와 HER둘다 문제를 해결하지 못하는 모습을 보였는데, 여기서 얼마나 reward shaping이 중요한지 확인했다고 합니다.
크게 두가지 이유가 위의 shaped rewards의 성능을 낮게 나오도록 한 원인으로 보았는데,
DDPG와 HER둘다 문제를 해결하지 못하는 모습을 보였는데, 여기서 얼마나 reward shaping이 중요한지 확인했다고 합니다.
크게 두가지 이유가 위의 shaped rewards의 성능을 낮게 나오도록 한 원인으로 보았는데,
- optimize하려는 것과 실제 성공적인 결과간의 불일치
- 안좋은 행동에대해 패널티를 주는 것이 exploration에는 안좋은 영향을 끼침 이러한 reward shaping을 하기 위해서는 domain 지식이 많이 필요함을 강조했습니다.
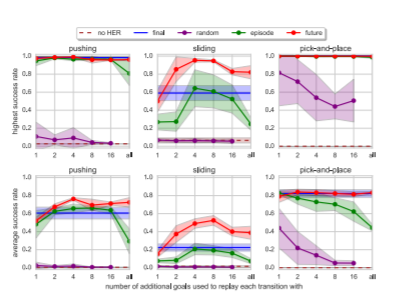
4.5 How many goals should we replay each trajectory with and how to choose them?
final
- 가장 Simple한 HER은 각각의 trajectory를 goal에 맞춰 replay하는데, 이 goal은 마지막 state에서 얻어집니다. 여기서는 실험적으로 다른 타입과 양의 goal을 Section 4.5에서 실험해 보입니다.
future
- 위의 전략과는 다르게, 같은 episode내의 k개의 random state를 뽑아, replay하고, 그 이후를 관찰합니다.
episode
- 같은 episode내의 k개의 random state를 뽑아, replay합니다.
random
- 전체중에서 random state를 뽑습니다.