World model
0.Abstract
비지도학습으로 environment의 compressed information을 따로 학습하는 Network를 구성해 따로 습득함으로써, 실제 Expected reward sum을 maximize하는 model의 크기는 줄여 좋은 성능을 냈습니다.(Credit Assignment Problem을 해결했다는데, neuron level에서도 모델이 크면 “어떤 뉴런에 가중치를 더 줘야하는지 이런 문제가 발생할수도 있겠다.”하는 생각이 듬)
1.Introduction
처음부터 정의를 하기엔 너무 어려우니 예를 들자면, 야구에서 타자가 어떻게 공을 치냐면, 공을 보고 어떻게 쳐야할지 뇌로 판단하기엔 너무 적은 시간을 가지니깐, 그 대신 경험적으로 그 공이 어디로 어떻게 갈지를 예측해 그 예측을 바탕으로 공을 치게됩니다. 공을 치는 것 자체에 두가지 process가 존재한다는 것입니다.
- 공이 어디로 언제 갈것인가
- 이렇게 온 공을 어떻게 칠 것인가
이 논문은 이 두 network를 어떻게 구성하는지에 대한 설명과 함께 그렇다면, 공이 언제 어디로 가는지 예측가능하다면 이걸 통해 image training하듯이 실제 외부 image data없이 actor를 학습하게 된다면 어떻게 될지에 대해 재밌게 풀어냅니다. model-free RL은 Network를 구성할 때 크게 만든다면, (여기서는) Credit Assignment Problem이 나타난다고 말하고, 작게만들면 실제 환경의 많은 parameter들을 다 학습해 낼 수 없게 된다고 합니다. 그렇기에 기본적인 논문의 구조는 large RNN-based agents라고 하는데, 이 agent는 두 가지 part로 구분됩니다.
- large world model
- small controller model
world model을 먼저 비지도학습으로 학습시키고, controller는 world model을 사용해 inference를 하도록 학습 시키겠다는 말입니다. 이를 통해 controller는 성능의 저하없이 적은 search space를 가져 학습에 수월해진다는게 논문의 주장입니다.
2. Agent model
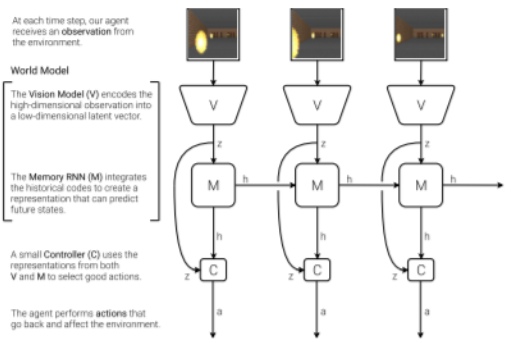 실제 우리가 가진 cognitive system에서 착안해, 1. visual sensory를 받아 encoding하는 vision model(high resolution의 image를 small representation으로 encoding해줌), 2. historical information을 이용해 future prediction을 하는 Memory RNN, 3. 그 데이터를 기반으로 예측을 하는 Controller model으로 구성되어 있습니다. 위의 분류를 조금 상세화하자면,
실제 우리가 가진 cognitive system에서 착안해, 1. visual sensory를 받아 encoding하는 vision model(high resolution의 image를 small representation으로 encoding해줌), 2. historical information을 이용해 future prediction을 하는 Memory RNN, 3. 그 데이터를 기반으로 예측을 하는 Controller model으로 구성되어 있습니다. 위의 분류를 조금 상세화하자면,
- large world model
- Vision model (V model)
- Memory RNN (M model)
- small controller model
- Controller(C model)
2.1 Vision model
Variational AutoEncoder를 통해 compressed representation을 만듭니다. 우리의 주안점은 여기가 아니니 빠르게 넘어가겠습니다. 자세한건 Appendix에 설명되어 있습니다.
2.2 MDN-RNN model
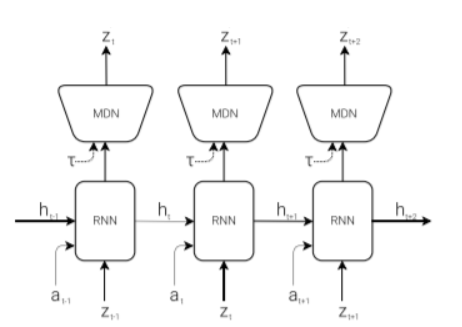 Vision model이 frame마다 agent가 볼 수 있는 image를 compress한다면, M model(MDN-RNN model)은 future prediction에 사용하는 역할을 합니다. 즉, Vision model에서 받은 z vector를 이용해, future z를 predict하는 역할을 합니다. 여기서 중요한 점은 많은 복잡한 환경이 stochastic함을 내재하고 있으므로, RNN의 output을 MDN에 넣어 deterministic prediction을 하는 게 아닌, probability로 inference한다는 점입니다.
Vision model이 frame마다 agent가 볼 수 있는 image를 compress한다면, M model(MDN-RNN model)은 future prediction에 사용하는 역할을 합니다. 즉, Vision model에서 받은 z vector를 이용해, future z를 predict하는 역할을 합니다. 여기서 중요한 점은 많은 복잡한 환경이 stochastic함을 내재하고 있으므로, RNN의 output을 MDN에 넣어 deterministic prediction을 하는 게 아닌, probability로 inference한다는 점입니다.
2.3 Controller Model
Controller model은 Expected Cumulative reward를 maximize하기 위한 역할을 가지고 있는데, 여기서는 Controller model을 최대한 작게 만드려고 노력했다고 합니다. 또한, Vision model과 M model과는 분리돼서(train할때 Vision model와 M model parameter는 freezing) 학습되었습니다. C model은 z와 h(V와 M의 output)을 각각받는 single linear layer로 구성되었습니다.
2.4 Putting V,M, and C Together
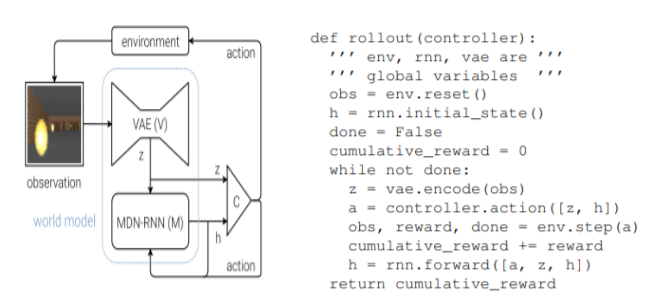 Vision model과 Memory RNN은 Neural Network를 이용하고, Controller는 parameter를 최소화하고, z,h를 이용해 최대의 성능만 내면 되므로(이전엔 visual vector나, 여러가지 encoding해야하는 정보량이 많았지만 아예 분리되었으므로) Controller를 train하기 위해선 꼭 Neural Network를 사용하지 않아도됩니다.
여기서 Controller는 Covariance-Matrix Adaptation Evolution Strategy(CMA-ES)라는 Algorithm을 사용해 학습하였는데, 이 알고리즘은 몇 천개의 파라미터에서 최적의 solution을 잘 찾아낸다고 알려져있습니다. 이를 이용해 C를 학습할 때엔, CPU를 이용하게 되었습니다.
의문 1:그렇다면, well-trained Controller없이 학습한 V와 M이 항상 좋은 성능을 낼 수 있을까?-? 이후 iterative한 방법으로 해결함
Vision model과 Memory RNN은 Neural Network를 이용하고, Controller는 parameter를 최소화하고, z,h를 이용해 최대의 성능만 내면 되므로(이전엔 visual vector나, 여러가지 encoding해야하는 정보량이 많았지만 아예 분리되었으므로) Controller를 train하기 위해선 꼭 Neural Network를 사용하지 않아도됩니다.
여기서 Controller는 Covariance-Matrix Adaptation Evolution Strategy(CMA-ES)라는 Algorithm을 사용해 학습하였는데, 이 알고리즘은 몇 천개의 파라미터에서 최적의 solution을 잘 찾아낸다고 알려져있습니다. 이를 이용해 C를 학습할 때엔, CPU를 이용하게 되었습니다.
의문 1:그렇다면, well-trained Controller없이 학습한 V와 M이 항상 좋은 성능을 낼 수 있을까?-? 이후 iterative한 방법으로 해결함
3 Car Racing Experiment
 Car Racing Environment는 자동차를 도로에서 벗어나지 않고 얼마나 잘 앞으로 나아가느냐에 대한 Environment입니다.
신기한건, edge-detecting, stacking recent frames 같은 추가적인 pre-processing 없이도 훨씬 잘 작동하였습니다. 또한 V model만 했을 때와, V model과 M model을 같이 했을 때의 실험결과를 보여주었는데 여러 궁금증을 해소시켜주는 좋은 논문이라고 생각이 들었습니다.
Car Racing Environment는 자동차를 도로에서 벗어나지 않고 얼마나 잘 앞으로 나아가느냐에 대한 Environment입니다.
신기한건, edge-detecting, stacking recent frames 같은 추가적인 pre-processing 없이도 훨씬 잘 작동하였습니다. 또한 V model만 했을 때와, V model과 M model을 같이 했을 때의 실험결과를 보여주었는데 여러 궁금증을 해소시켜주는 좋은 논문이라고 생각이 들었습니다.
3.4 Car Racing Dream
그렇다면, z_t를 가지고 M model에서 z_(t+1)의 distribution을 얻으면, 거기서 sampling해서 계속 진행시키면 어떻게 될까에 대한 의문을 가지고 실험해보았는데 이를 Dream이라고 표현했습니다.
4. VizDoom Experiment
 VizDoom은 앞의 enemy가 던지는 fireball을 피해 오래 살아남는 게임입니다.
여기서는 3.4에서 생긴 의문을 풀어주는 experiment를 진행합니다.
3.4와 같은 의문을 가진다면, 우리는 이 dream에서 learning을 진행하고 transfer할 수 있을까? 에 대한 물음을 던집니다. 그리고 이 VizDoom 이란 environment에서 실험을 진행하는데, 4.1, 4.2에서 실제 환경에서와 Dream에서 진행할 때에 차이점에 대해, Car Racing에서와의 차이점에 대해 설명합니다.
VizDoom은 앞의 enemy가 던지는 fireball을 피해 오래 살아남는 게임입니다.
여기서는 3.4에서 생긴 의문을 풀어주는 experiment를 진행합니다.
3.4와 같은 의문을 가진다면, 우리는 이 dream에서 learning을 진행하고 transfer할 수 있을까? 에 대한 물음을 던집니다. 그리고 이 VizDoom 이란 environment에서 실험을 진행하는데, 4.1, 4.2에서 실제 환경에서와 Dream에서 진행할 때에 차이점에 대해, Car Racing에서와의 차이점에 대해 설명합니다.
4.3 Training Inside of the Dream
Dream은 M model에서 관장합니다. M model은 실제 Environment를 얼마나 잘 묘사(game logic, enemy behaviour등에 대해)할 수 있을까요? 실제로 M model에서 enemy는 fireball을 발사하고, 움직이기도 하면서 agent의 움직임 또한 어느정도 묘사해냈습니다. 하지만 softmax를 할 때, 사용되는 temperature를 올리면 실제 환경보다 어렵게 되었고,(좀더 next state에 대해 random하게 inference하므로) 가끔은 agent가 이유없이 죽기도 하였습니다.(이 죽는것 또한 dream내의 M model이 판단하는 것이기 때문에 M model이 완전 잘 학습되지는 않았다고 볼 수 있습니다.)
4.4 Transfer Policy to Actual Environment
또한 실제 detail을 잡아내지 못했고,(enemy가 몇명인지 정확히 catch해내지 못하고 실제 environment보다 더 어려운 환경이 되어진채로 학습이 진행됩니다. 하지만 enemy가 몇명이든 날아오는 fire ball만 피하면 되므로 성능에는 지장이 없을 수 있었습니다.)
4.5 Cheating the World Model
Controller는 M model의 Dream에서 Cheating을 하기 시작하는데, 특정하게 움직이면 fireball을 발사하지 못한다던지, fireball을 만들고 있을 때, 확 움직이면 fireball이 사라지는 행위를 이용해 cheating을 하는 policy를 만듭니다. 이는 M model이 실제 environment를 모델에 대해 확률적인 근사를 하였기 때문에 정확히 묘사해내지 못했기 때문이라고 할 수 있습니다. 이를 여기서는 이렇게 표현합니다. “하늘에 있는건 떨어진다고 배우는데(실제 environment) 어린아이의 상상으로는(M model) 지구를 나는 슈퍼히어로를 상상할 수 있다.” 여기서는 Controller가 Memory RNN 내의 모든 hidden state에 접근할 수 있도록 하였는데,(이 정보를 모두 input으로 받을 수 있도록) 이는 Controller가 단순히 보여지는 화면만을 가지고 policy를 세우는 것보다 게임 내부의 모든 rule을 모두 보는 것이 당연하다고 생각했다고 합니다. 이 것의 문제점은 위에서 봤듯이 Controller가 M model내의 adversarial policy(4.3에서의 cheating을 일으키는 policy)를 알아내기 쉽다는 점입니다. 그러므로 실제 environment에서 좋은 policy를 찾기보다, M model을 속이기 쉬운 쪽으로 학습을 하게되어 실제 state distribution과 학습하는 state distribution의 괴리가 생기게 됩니다. 이러한 이유가 M model같은 model이 지금까지 실제 환경을 대체하지 못했던 이유일 것이라고 설명하고 있습니다. 이전의 M model역할을 수행했던 M model에 대해 deterministic model, Bayesian model, RNN M(Controller can ignore a flawed M) 역사를 설명하고, Controller를 simplify한 contribution에 대해 설명합니다. 마지막으로 위에서 살짝 언급했던 z_(t+1)을 sampling할 때, softmax의 temperature에 따라 Dreaㅈm과 실제 environment에서의 performance를 비교하자면 이렇게 됩니다.
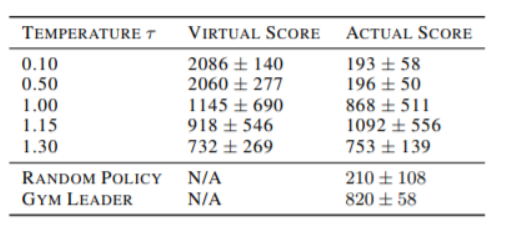 위에서 들었을 의문일 수 있지만, deterministic 환경에서 MDN을 적용하는 것 자체가 과한거 아니냐? 싶었겠지만, temperature을 0.1을 주면(거의 deterministic) overfit된 것을 보실 수 있습니다.(enemy가 fireball을 안쏘는 등의 행위를 하므로 dream 에서의 score는 높음.)
위에서 들었을 의문일 수 있지만, deterministic 환경에서 MDN을 적용하는 것 자체가 과한거 아니냐? 싶었겠지만, temperature을 0.1을 주면(거의 deterministic) overfit된 것을 보실 수 있습니다.(enemy가 fireball을 안쏘는 등의 행위를 하므로 dream 에서의 score는 높음.)
5. Iterative Training Procedure
위에서 의문 1이 해결되는 순간입니다. 위의 environment는 비교적 쉬운 환경에서의 M model을 만든 것이니 좀더 복잡한 환경에 대해(random policy로는 생성시킬 수 없는(좋은 policy에서만 나오는)) 어떻게 커버할 것인가를 해결시켜줍니다. 이때는 iterative하게,updated agent가 환경을 돌아다니고, 새로운(좋은) observation에 대해 M model을 update하는 식으로 진행됩니다. 정말 신기한게,iterative하게 M model을 학습한다고 봤을 때 들었던 생각이, “이 M model fitting에 나오는 loss를 Controller가 exploration하는데에 사용할 수 있겠다” 싶었는데 딱 그 얘기를 합니다. 또한, Iterative하게 M model을 학습하므로, 학습된 M model을 통해 Controller를 얻고, 이 M model에 대해 좋은 Controller를 통해 또 environment를 M model이 학습된다는 것 자체가 복잡한 환경에 대해서 필요하다고 합니다.
6. Relative Work
이전의 M model들로는, PILCO는 Gaussian Process로 environment를 학습했었고, Gaussian Process는 low dimension에서는 잘 작동하지만, high dimension에서의 적용이 어려웠습니다. 이는 실제 우리가 적용하려는 여러 분야에서 적용시키기 어렵다는 말과 같습니다. 그렇기에 이를 압축된 hidden state로 만드려는 노력들이 있었고, 실제 더 좋은 성능을 보였습니다. 이처럼, 미래를 완벽히 예측할 수 있는 M model이 있다면, 실제로 그냥 미래에 받을 수 있는 reward가 큰 action을 취하면 되기 때문에 이는 단순히 예전부터 연구되던게 아니라, 계속 여러 분야에서 다양하게 연구가 되고 있었습니다. 그렇기에 Learning to Think는 RNN 계열로 environment를 나타내려는 시도를 하였고, 이는 M model을 이용하는데 더 많은 발전을 주었습니다.
- Discussion
M model을 만드는 것은 다음과 같은 장점이 있습니다.
실제 environment와 interaction에 비용이 많이들 때, 이 interaction을 줄이거나 없앨 수 있다.
Controller가 실제 environment의 raw high dimensional data를 정제한 M model에 대한 hidden에 모두 접근함으로써, 필요한 정보만을 얻어낼 수 있다.
실제 training을 위한 Network는 크기가 작아 학습이 굉장히 빠름.(data efficiency)
단점으로는,
그 환경을 학습시키기 위한 추가적인 학습
- M model Network의 한계 -> future work
- M model Network Architecturing VAE를 쓰는 standalone하게 쓰는 것도 한계가 있었습니다. 중요한 information을 잘 캐치하지 못하거나, 불필요한 타일 패턴같은 것은 잘 잡아내기도 하였습니다. 이를 해결하기 위해 Controller와 함께 학습하게 되면, 좋을 수 있는데, 이는 그렇다면 또다시 M model과 Controller가 결합됨으로써, 이전의 학습과 비슷하게 되어져버립니다.(여기서는 effectively reuse가 어려워진다고 말합니다.)
여기까지 기술적인 부분과 Experiments에 대해 모두 살펴보았고, 좀더 이해가 필요한 부분은 Appendix에 실어놓은 친절한 논문입니다…(Variational AutoEncoder, RNN, Evolution Strategies에 대해 설명해져 있습니다.)