Never Give Up : Learning Directed Exploration Strategies
Abstract
이 논문은 exploration이 주가 되는 게임에서 강점을 보이는 논문입니다. 여기서 intrinsic reward를 이용하였는데, 이는 episodic reward와 inter-episodic reward로 나뉩니다. episodic reward는 k-nearest neihgbors를 사용하여 한 episode내에서 얼마나 새로운지를 판단해 reward를 내리는 self-supervised 기법입니다. 그리고, Universal Value Function Approximators( UVFA)를 이용해, exploration과 exploitation의 trade-off를 맞추며, 다양한 exploration polices(exploration을 위해 여러 policies를 가집니다.)를 배우도록 합니다. 이렇게 한 네트워크가 다른 정도의 exploration과 exploitation을 함으로써, 효과적인 exploratory policies가 효과적인 exploitative polices를 생산한다는 것으로 부터 설명됩니다.
#여기서 policy는 network를 뜻하지 않습니다. 헷갈리지 않길 바랍니다.
1. Introduction
Exploration에 대한 역사를 설명하는데, stochastic policies를 사용하여 dense reward scenarios에서 이를 해결한 paper부터, 최근에는 exploration을 유도하기 위해 intrinsic reward를 사용함을 소개하며, 지금 state가 이전에 방문했던 state들과 얼마나 다른지를 사용해 어려운 exploration을 해결한 paper들 또한 소개합니다. 하지만 이에 대해서도 근본적인 한계가 있음을 지적합니다. state에 대한 novelty가 사라지면, exploration이 더 필요하든 말든, 다시 그 state를 가려는 intrinsic reward가 현저히 줄어들어버리기 때문입니다.
다른 방법으로는, prediction error를 사용하는 방법이 있습니다. 이 방법 역시 high cost이면서, 모든 환경에 일반화하기 어렵습니다.
이 논문의 메인 아이디어로는 exploration과 exploitation을 같은 network로 부터 함께 배우는 것입니다. 이는 exploitative policy는 extrinsic reward에 집중하면서도, exploratory policy는 올바른 방향으로 exploration을 유지한다는 뜻입니다. 이를 해결하기 위해 UVFA의 framework을 사용했고, 다양한 exploratory policies를 사용합니다.
여기서는 intrinsic reward를 두가지로 나눠 정의합니다.
- per-episode(Episodic) novelty
- 이 novelty는 한 episode내에서의 novelty이므로, episode 전체로 봤을 땐, familiar한 state도 revisit하게 해줍니다.
- 한 episode내의 방문한 state들을 encoding시켜 저장합니다.
- 여기에서 사용하는 similarity(novelty의 반대)는 이전에 저장된 state과의 similarity입니다.
- life-long novelty
- 이 novelty는 점진적으로 familiar한 state일수록 낮습니다.
- Random Network Distillation error로 규정합니다. 이러한 두 가지 novelty의 결합은 complex task, high dimensional state space에서의 관측되지 않은 state에 대한 일관성과 episode 내와 episode사이에서의 일관성있는 exploration을 유지하도록 돕습니다.
이 논문의 contribution은 다음과 같습니다.
- exploration bonus를 정의해(episode내부와 episode간의 novelty로) training process내에서 exploration을 계속 유지하도록 합니다.
- 위에서는 그냥 exploration이라고 적었지만, 사실 seperate exploration을 합니다. 여러 parameter들을 가지고, exploration policy를 사용하는데, 이후에 설명하도록 하겠습니다.
- 어려운 exploration이 필요한 게임에서 기존 SOTA보다 좋은 성능을 보였습니다.
2. The Never-Give-Up Intrinsic Reward
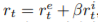 time t에서의 reward는 extrinsic reward와 intrinsic reward의 합으로 구성되는데, beta는 positive weights이다. performance를 측정할 때는 extrinsic reward만을 통해 성능을 측정했고, 이제 intrinsic reward에 대한 설명을 하려고 합니다.
time t에서의 reward는 extrinsic reward와 intrinsic reward의 합으로 구성되는데, beta는 positive weights이다. performance를 측정할 때는 extrinsic reward만을 통해 성능을 측정했고, 이제 intrinsic reward에 대한 설명을 하려고 합니다.
intrinsic reward는 다음과 같은 세가지 성질을 가지고 있습니다.
- 첫째로, 빠르게 한 episode내에서 같은(비슷한) state를 재방문 하지 않도록 합니다.
- 둘째로, 천천히 inter-episode에서 많이 방문한 state를 방문하지 않도록 합니다.
- 셋째로, agent의 action에 영향을 받지 않은 environment의 state를 무시합니다.
다음은 intrinsic reward를 어떻게 계산하는지 overview를 보겠습니다.
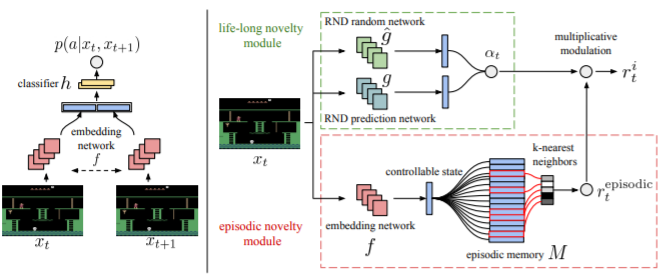
위에서 설명한 intrinsic reward와 extrinsic reward를 구하기 위해 network는 두가지 block으로 나뉘고, 각각 episodic novelty module(빨간색)과 life-long novelty module(녹색)로 부릅니다.
- episodic novelty module
- episodic memory(M)와, embedding function(f)로 구성되어 있습니다.
- memory M은 새 episode마다 비워지고, 각 스텝마다, episodic intrinsic reward가 계산됩니다.(계산되기 위해서 memory M에서 비교가 일어나야합니다.) 또한 controllable한 state를 memory M에 저장합니다.
- function f는 current controllable state를 representation으로만들기 위함입니다.
- episodic novelty는 agent가 한 episode내에서 다양한 state를 수집하도록 유도하는 역할을 합니다. 그러므로, inter-episode에서는 자주 일어났던 state라도 episodic novelty는 높을(새로울) 수 있습니다.
- episodic memory(M)와, embedding function(f)로 구성되어 있습니다.
- life-long novelty module
- inter-episode에서의 novelty를 계산합니다. 이는 alpha로 표현합니다.
이 둘을 결합해 intrinsic reward를 만듭니다.
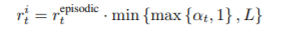
L은 scaling을 위해 존재하고 5로 잡아서 사용했습니다.
- Embedding Network
- current observation을 p-dimension의 vector로 controllable state만 변환해주는 network에 대한 설명입니다. 이 논문에서는 state에서 agent가 제어할 수 없는 요소는 의미있는 exploration을 하도록 만들지 않는다고 판단했고, 이를 방지하기 위해 Siamese network를 만들어 사용했습니다. 이를 통해, state와 next state가 들어갔을 때, action을 output으로 가지도록 학습시키게 됩니다.
- Episodic memory and intrinsic reward
- Episodic memory M은 dynamic size를 가진 memory입니다. controllable state를 embedding한 data를 가지고 있으며, 이 때, episodic reward는 다음과 같이 주어지게 됩니다.
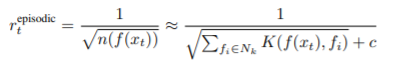
- 이때 kernel function K는
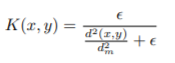 과 같은 방식으로 구하게 됩니다. d^2_m은 k개의 nearest states와의 거리의 제곱의 평균, d^2는 그 k개의 states들과의 각각의 거리 제곱입니다. 쉽게 normalize한 것입니다.
과 같은 방식으로 구하게 됩니다. d^2_m은 k개의 nearest states와의 거리의 제곱의 평균, d^2는 그 k개의 states들과의 각각의 거리 제곱입니다. 쉽게 normalize한 것입니다. - Integrating life-long curiousity
- 여기서는 life-long curiousity를 Random Network Distillation을 통해 구하였고, alpha는 다음과 같이 구하게됩니다.
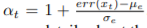
3. The Never-Give-Up Agent
이 Section에서는 앞에서 발생시킨 intrinsic reward를 어떻게 agent의 학습과정에 합칠지에 대해 설명합니다. 하지만 이 전에, intrinsic reward를 주는 것 자체가 MDP를 POMDP로 바꾸는 것을 의미합니다.(intrinsic reward에 대해 MDP가 성립하지 않음) 그렇기 때문에 이를 해결하기 위해 두가지 접근법을 제시했습니다.
- 첫째로, intrinsic reward를 agent의 input으로 그대로 넣는 방식을 취했습니다.
- 둘째로, agent가 episode내에서 있엇던 모든 internal state representation을 가지고 있도록 했습니다. 그리고 agent는 R2D2를 base로 두고 구현하였습니다.
다른 intrinsic reward paper들과는 다르게, NGU는 intrinsic reward가 소멸되지 않으므로, 이것에 의해 policy는 driven됩니다. 거기다가 exploratory behaviour는 value function으로 encoding되고, 이는 쉽게 꺼지지 않기 때문에 이를 해결하기 위해, extrinsic reward에만 driven되는 exploitative policy를 함께 학습합니다.
- Proposed architecture
- UVFA의 idea를 사용해,
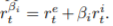 의 형태의 reward를 가지고 학습합니다. 이 때 beta는 0부터 특정 값까지 discrete하게 나눠서 사용하는데, 이는 experiments와 App. H.3과 App. F.에서 자세히 살펴볼 수 있습니다.
의 형태의 reward를 가지고 학습합니다. 이 때 beta는 0부터 특정 값까지 discrete하게 나눠서 사용하는데, 이는 experiments와 App. H.3과 App. F.에서 자세히 살펴볼 수 있습니다.
- UVFA의 idea를 사용해,
- RL Loss function
- Retrace double Q-learning loss 를 사용하고 App.E에서 자세히 살펴볼 수 있습니다. gamma도 beta의 i에 맞춰서 0.999부터 0.99까지 존재하고, 가장 exploratory policy에는 작은 discount factor를 사용했는데, 이는 intrinsic reward가 dense하고, 값의 범위가 충분히 작았다고 설명합니다. exploitative policy는 반면에 거의 undiscounted return과 비슷하게 하려고 했습니다.
- Distributed training
- 최근에는 distributed training structure들의 좋은 성능을 보았기 때문에, 여기서도 그 구조를 착안하였습니다.