Distributed Prioritized Experience Replay
Abstract
이 논문은 분산 강화학습에 대해서 effactive하고 scalable한 architecturing에 주목한 논문입니다. actor와 learner를 분리하여 actor는 환경에서 trajectories를 만드는데 집중하고, 그 trajectories를 centralized memory에 저장합니다. learner는 centralized memory에서 trajectories를 sampling하여 network를 업데이트 합니다. 이 때, priortized experience replay(PER)를 효과적으로 이용하는 방법론이 이 논문의 가장 흥미로운 포인트였습니다.
1. introduction
이 시점의 트랜드로써 좋고 큰 모델에 많은 데이터를 넣어 많은 연산이 있더라도 좋은 결과를 내는 것에서 흥미로운 연구 결과들이 나오고 있었습니다. 이러한 연구 결과가 RL에서도 비슷한 효과가 있을 것임을 기대하는건 당연한 일인데, 이전의 RL paper들로 Gorila나 A3C, DPPO등의 예를 볼 수 있습니다. 앞에서 설명한 바와 같이 이 논문도 Deep RL에서의 scaling up을 어떻게 다룰 것인가에 대한 논문이고, off-policy인 RL algorithm의 특성을 이용해 Actor와 Learner를 쉽게 분리할 수 있었으며 거기에 PER를 많은 computation 없이 추가한 것이 main contribution으로 보았습니다.
2. Background
Distributed Stochastic Gradient Descent
- 이 기법은 지도학습계열에서 먼저 neural network의 학습을 빠르게 하기 위해 parallelizing하는 방식으로 사용되었습니다. 동기적과 비동기적으로 업데이트 하는 방법이 있는데, 둘다 효과적임을 보였고, 표준이 되었습니다. 이를 강화학습에서 비동기적으로 업데이트 하는 방식이 활성화되어 GA3C와 PAAC등이 사용되었습니다.
3. Our Contribution : Distributed Prioritized Experience Replay
이 논문에서는 PER을 distributed setting으로 확장시켰고, 높은 확장성을 갖는 방법임을 보입니다. 이런 방법을 Ape-X라고 명명하였습니다.
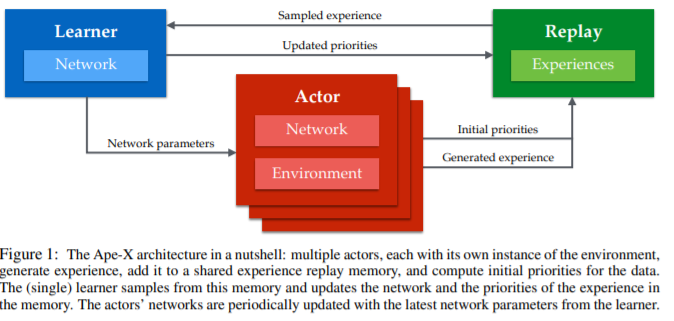
 사실 기본 algorithm은 정말 간단합니다. 기존의 PER를 안보셨다고 해도, Actor와 Learner가 분리되어 각 Actor는 learner의 buffer에 Local buffer를 sampling해서 처리해 넣고, learner는 그 buffer를 이용해 update하는 형식입니다. 중요하게 볼점은,
사실 기본 algorithm은 정말 간단합니다. 기존의 PER를 안보셨다고 해도, Actor와 Learner가 분리되어 각 Actor는 learner의 buffer에 Local buffer를 sampling해서 처리해 넣고, learner는 그 buffer를 이용해 update하는 형식입니다. 중요하게 볼점은,
- actor는 local buffer를 가진다.
- centralized memory(replay memory)에 보내기전에 priorities를 계산해 넣는다.
- 주기적으로 learner의 parameter로 update함으로써 2번에서 넣는 priorities가 learner가 계산하는 priorities와 크게 차이나지 않게 계속 얻어질 수 있다.
정도입니다.
trajectories를 sharing하는 것이 gradients를 sharing하는 것보다, 기본적으로 data가 쓸모없는 data가 되는 속도가 느리고, algorithm이 off-policy에 강하기 때문에 장점이 많습니다.
또한 actor마다 여러 exploration polices들을 주는 등 exploration problem등에서 좋은 면을 보여줄 수 있는 장점들이 있습니다.
3.1 Ape-X DQN
- Ape-X는 여러 framework에 응용 될 수 있습니다. 그렇기에 여기서는 double Q-learning과 multi-step bootstrap targets을 learning algorithm으로 정했고, dueling network architecture를 선택하였습니다. 결과적으로 다음과 같은 수식으로 update를 합니다.

보시는 것처럼 multi-step Q_learning를 사용하는데 이때 이론적으로는 correction(truncate등의)이 필요한데 실험적으로 다양한 exploration을 가진 actor로부터 multistep이 나와서 correction하기도 애매하기도하고, prioritization을 사용하기 때문에 그냥 이대로 사용했다고 합니다.
3.2 Ape-X DPG
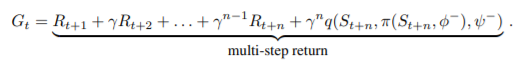
Ape-X의 generality를 테스트하기 위해 continuous한 환경에서의 실험도 빠지지 않았는데, off policy algorithm인 DDPG의 multi-step algorithm을 그대로 적용할수 있음을 보이면서 메인 아이디어가 끝이 납니다.