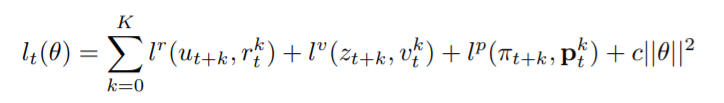한줄요약 : 이전까지의 Model-based는 이래서 별로고 저래서 안됐고 하는게 항상 새로운 SOTA로 변화할 때마다, 이전의 문제들을 객관적으로 바라보고 reasonable하게 해결하는게 놀랍다고 느꼈다.
Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
Abstract
주어진 환경에서 agent의 미래 policy를 계획하는 능력은 예전부터 주된 과제들 중 하나였고, Alphago와 같이 Tree-based planning이 이 도전적인 분야를 해결했습니다. 하지만 이는 완벽한 simulator가 주어져야만 했으며, 실제 환경에서는 그렇게 dynamics가 복잡하거나 안알려져 있는 경우가 많습니다. 이 연구는 그래서 MuZero라는 알고리즘을 연구했으며, 이는 학습된 모델과 tree-based search와의 결합으로 인해 dynamics의 정보가 없는 경우에서 큰 성공을 거두었습니다. MuZero는 planning에 연관된 reward, policy, value function 들을 iterative하게 예측하는 모델을 학습합니다.
introduction
model-free algorithm은 정확하고 정교하게 앞을 예측해야하는 경우에 SOTA보다 떨어지는 경향을 보입니다. 이논문에서는 Muzero라는 model-based algorithm을 소개하는데, 이는 AlphaZero의 tree-based search방식과 search-based policy iteration을 가지고, learned model을 학습과정에 융합시켜서 학습합니다.
메인 아이디어는 다음과 같습니다. (1) model이 observation을 받은 뒤, hidden state로 변환합니다. (2) hidden state는 이전의 hidden state와 model내에서 선택된 action(실제 action이 아닌)을 통해 update됩니다. (3) 이 과정의 매 스텝에서 모델은 policy와 value function, reward를 예측하게 됩니다.
이 모델은 end-to-end로 학습되며, 단순히 세 가지(policy, value function,reward)의 예측값의 정확도를 올리도록 하나의 objective로 학습됩니다. 여기에는 observation을 다시 복원하기 위한 모든 것을 hidden state로 가져가야하는 직접적인 제약이나 요구사항이 없습니다. 단지 위의 세가지를 잘 나타낼 수 있도록 hidden state로 만들어 주면 되기 때문에, 쓸모없는 정보들이 간소화되면서 성능이 올라감을 알 수 있습니다.
Prior Work
RL은 Model의 유무에 따라 Model-free와 Model-based로 나뉘어진다. Model-based는 environment의 model을 만드는데, 이는 MDP로 이루어집니다. MDP는 두가지 구성요소가 있는데, state transition과 reward입니다. 한번 모델이 만들어지면, MDP value iteration과 MCTS 같은 planning algorithm을 적용할 수 있는데, 이는 MDP의 optimal value또는 optimal policy를 계산하기 위한 algorithm입니다. 큰 환경이나 POMDP같은 상황에서는 model이 predict할 수 있는 state representation을 먼저 만들어야 하는데, 이러한 representation을 배우고, model을 배우고, planning을 하는 세가지로 나누게 된다면 cumulative error를 피할 수 없어 효과적인 planning이 불가능하게 됩니다.
-
주요한 접근법으로는 pixel level에서의 접근이 있었습니다. 그러나 pixel-level에서의 세밀함은 크기가 큰 문제에서 쉽지 않을 뿐더러, planning에 필요하지않은 곳에까지 세밀함을 가지고 있어 model-free에 비해 좋지않은 성능을 보이고 있었습니다.
-
다른 접근으로는, 최근에 발전된 방법인데, value function을 predicting하는 것입니다. 메인 아이디어는 실제 environment를 planning하는 것처럼 추상적인 MDP에서 추상적인 model을 만드는 것입니다. 이는 실제 한 state에서 시작해, abstract MDP의 cumulative reward를 실제 environment에 맞추는 방법인 value equivalence을 통해 이루어집니다. 이러한 방법은 action없이 value를 predicting하는 방식에서 시작했는데, model은 MDP를 따랐지만, 실제 environment의 state를 맞추기 위한 transition model이 필요없었고, 그저 neural network의 hidden layer정도로만 여겨졌습니다.
Value equivalent model은 action을 포함하여 value를 optimize하는 형식으로 확장되었는데 TreeQN은 abstract MDP model을 배우고, optimal value function을 approximate합니다. Value iteration network는 local MDP model을 배우고, optimal value function을 근사하였습니다. Value prediction network는 MuZero와 가장 근사한데, 실제 action으로부터 MDP를 배웁니다.
MuZero Algorithm
Model은 각 내부 스텝마다 representation function, dynamics function, prediction function으로 구성됩니다.
그림으로 보면, actual state를 hidden state로 바꾸어주는 representation function, 이 정보를 가지고, policy와 value를 예측하는 prediction function, 마지막으로 sampling된 action(not actual action)과 함께 reward와 next hidden state를 예측하는 dynamics function이 있습니다.
이 모델로부터 MCTS를 결합해 사용하는데, AlphaZero와 비슷하게, policy target과 value target은 MCTS search로인해 업데이트되지만, AlphaZero와 다른점은, n-step bootstrapping을 사용한다는 점입니다.
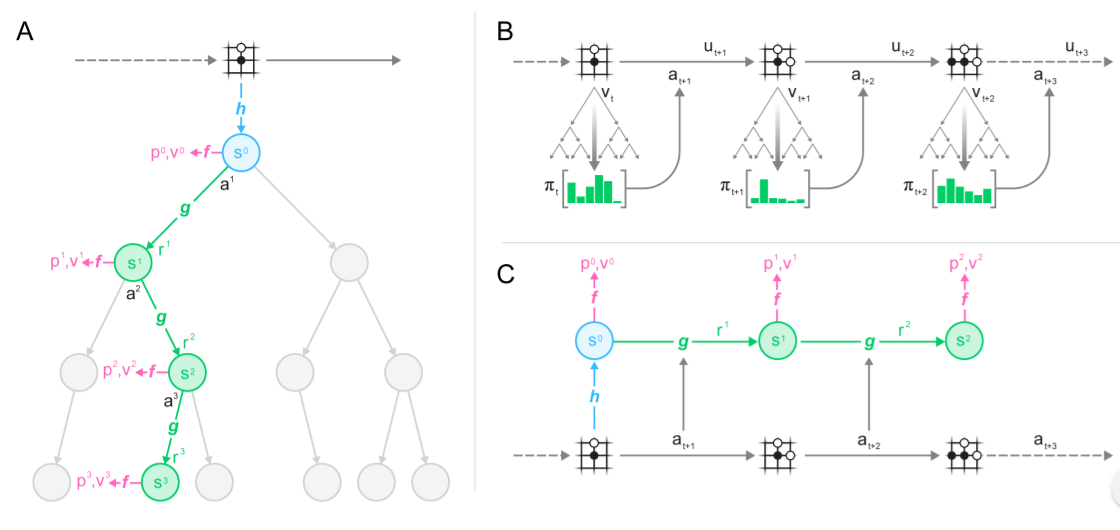
결국 다음과 같이 loss는 predicted policy p와 search policy u의 l2 loss, predicted value v와 value target z의 l2 loss, predicted reward r과 observed reward u의 l2 loss, L2 regularization으로 구성됩니다.