Abstract
- Expert의 Demonstrations(trajectories)를 가지고 imitation 하도록 배우는 것은 challenging한 일입니다. 특히, environment가 high-dimensional하거나, continuous observation을 가지거나 dynamics를 모를때 이런 문제는 더욱 심화됩니다. Imitation learning에서 가장 간단하게 Offline으로 expert를 학습시킬 수 있는 방법은 behavioral cloning(BC)입니다. 이는 greedy하게 demonstration안의 어느 state에 대해 expert의 action을 따라하도록 supervised learning 방법으로 학습됩니다. 이 때, actor의 action과 expert의 action의 오차에서 오는 차이와 함께 dynamics의 stochastic한 성격으로 인해 오차가 점점 쌓여 성능에 악영향을 끼치게 됩니다. 이러한 문제를 해결하기 위해 InverseRL이 계속 발전하였는데 특히 GAIL이 adversial network를 도입함으로써 expert demonstrations와 agent의 trajectories를 통해 cost function을 학습하는 방법으로 획기적인 진전을 이루어 냈습니다. 하지만 이러한 방법도 adversiarial network를 사용함으로 오는 학습의 불안정성이 존재합니다. 이 논문은 애초에 reward function을 구하기 위한 노력을 하지 않는데, agent에게 demonstration의 distribution을 벗어났을 때, 돌아오도록하여 long horizon동안 demonstration과 크게 벗어나지 않도록 하였습니다. 이를 달성하기 위해 생각보다 간단한 방법을 사용하였는데, agent는 demonstrated state에 대해 demonstrated action을 했을 때 reward + 1, 이외에는 0을 줌으로써 학습하였습니다. 이 방법을 Soft Q Imitation Learning(SQIL)이라고 명명하였고, 실험적으로 여러 benchmark에서 GAIL이나 BC보다 좋은 성능을 보였습니다.
Introduction
- 이 논문은 기존의 GAIL같은 adversarial network를 구성하지않고도 demonstrated state를 방문할 수 있도록 하는 능력을 agent에게 학습시킬 수 있는 방법을 제시합니다. adversarial network를 사용함으로써 얻는 장점에 대해 두 가지를 나열해보자면, 첫째로, 가장 간단하게 BC에서 얻는 것과 같은 Demonstrated states에서의 demonstrated actions을 따라하는 능력입니다. 둘째로 BC로 얻지 못하는 새로운 state(out-of-distribution in demonstration)를 맞닥뜨렸을 때, 다시 demonstrated states로 돌아오는 능력입니다. 이 논문은 간단한 상수의 reward를 통해 adversarial network없이(cooperative network와) 학습을 진행합니다. reward는 demonstrated state에서 demonstrated action을 했을 때 +1, 이외에 0을 주는 방식입니다.
- 이 때, 이렇게 optimize하는 방식은 theoretical하게 regularized BC의 변형으로 볼 수 있는데, 이를 section 3에서 설명합니다. 자세한 설명은 생략하도록 하겠습니다. regularized BC의 loss는 결국 reward에 entropy를 maximize하려는 의도와 같다고 판단했습니다.
- 결과적으로 이 논문의 contribution은 BC의 단점을 극복하면서, adversarial training과 reward function없이 학습한다는 장점이 있습니다. 또한 Q-learning계열의 간단한 변형으로 쉽게 구현 또한 가능합니다.
Soft Q Imitation Learning
- 구현이 쉬운만큼 알고리즘 자체는 어렵지 않습니다. 앞에서 설명했던 내용을 좀 더 자세하게 설명하자면, Q-learning계열의 학습에서 세 가지 변형을 통해 SQIL는 학습을 진행하는데 이는 다음과 같습니다.
- Demonstrations를 experience replay buffer에 reward := + 1를 넣어 저장합니다.
- agent가 environment와 interaction하여 얻은 새로운 trajectories는 reward := 0 로 저장합니다.
- 학습시에 이 새로운 experiences와 expert의 experiences의 비율을 맞춰 학습을 시키면 됩니다.
-
그리고 Soft Q-learning을 통해 optimize하는데, 이는 off-policy learning이고, imitation learning에서 on-policy method보다 큰 장점을 보이는 점중 하나로, agent가 positive reward를 받기 위해 꼭 demonstrated states를 방문할 필요 없이 expert의 demonstrations을 재현하려고만 학습하면 된다는 점 입니다.
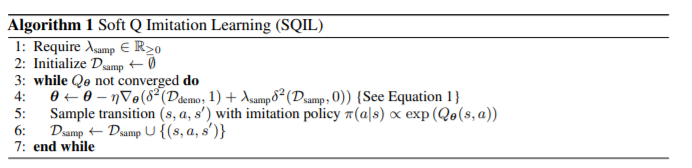
SQIL의 algorithm은 다음과 같습니다.line 4의 \(\delta^2\)는 sqaured soft Bellman error 연산으로, 이는 다음과 같습니다.(Equation 1)
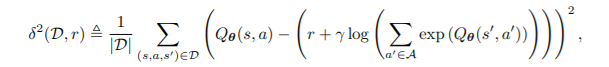
Soft Q-learning의 Q loss function입니다. entropy를 최대화 하려는 의도가 있습니다. 자세한 내용은 soft Q-learning의 논문을 참조하시면 좋을 것 같습니다. 이 때, reward는 state나 action에 영향을 받지 않는 constant function임을 볼 수 있습니다. 그리고 $\lambda_{\mathrm{samp}}$는 hyperparameter로 실험적으로 1을 넣어도 잘 working하는 것을 볼 수 있었다고 합니다algorithm설명은 위에서 설명한 그대로이므로 생략하겠습니다.
- 이 때, 들 수 있는 의문점은, 점점 agent가 expert와 비슷한 action을 취하게 될 것인데, 이 때도, sparse한 reward system을 계속 유지할지에 대해 의문이 들 수 있습니다. 이에 대해 experiments를 50 : 50으로 넣어주는 것이 effective reward의 하한을 만든다고 합니다. 실전적으로 SQIL의 loss가 한 번 수렴했을 때, training을 멈춘다면 agent의 performance에 악영향을 끼치지 않는다고 하는데, 이러한 테크닉을 GAIL이나 AIRL에서 overfitting등을 피하기 위한 방법으로 쓰인 것을 보이면서 같은 맥락이라고 말합니다.
Interpreting SQIL as Regularized Behavioral Cloning
- Soft Q-learning의 loss 자체가 entropy를 maximize하려고 하기 때문에 RBC의 loss에 당연히 비례할 것이라고 생각은 했기에 더 읽어보지는 않았습니다.