Abstract
- 이 논문은 High-dimensional input에 대해 RL agent가 Auxiliary task를 수행함으로써 feature representation을 빠르게 배울 수 있는 방법에 대해 소개합니다. 이는 몇몇 benchmark에서 기존의 image기반의 model-based, model-free method를 능가하는 모습을 보입니다.
Introduction
- image-based agent들은 같은 task이더라도 state-based보다 sample-efficiency가 낮은 경향이 있습니다. 이는 당연하게도 scratch에서, 유용한 정보을 추출해내는 일이 image-based일 때 좀 더 어렵기 때문입니다. 이 때, image-based이더라도 알맞은 정보를 잘 추출해낸다면 학습속도를 크게 향상시킬 수 있겠다는 것이 이 논문의 기본 아이디어입니다.
- 기존의 RL 연구들에서 sample-efficiency를 높이기 위해서 크게 두 가지 방향의 연구가 있습니다.
- Auxiliary task를 수행하는 방법
- self-supervised learning method를 통해 학습 속도를 높입니다.
- 둘째로 model을 배우는 방법
- environment의 model을 배우는 방법을 통해 학습 속도를 높입니다. 특정 시점 t 이후의 state, value등을 예측하는 방법이 쓰입니다.
- Auxiliary task를 수행하는 방법
- 이 논문은 첫번째 방법에 속하는데, 특히 computer vision 계열에서 큰 진전을 이루었던 contrastive learning의 영향을 받았습니다. 하지만 그대로 적용하기에는 vision에서와 환경이 조금 다른데, 크게 두 가지를 꼽자면,
- 첫째로, 큰 규모의 라벨링되지않는 데이터셋을 이용할 수 없습니다. observation에 대해 그때 그때 얻으므로 그 것을 사용해야만 합니다.
- 둘째로, unsupervised training과 reinforcement learning이 동시에 진행됩니다.
- 이 논문은 이 두 가지 문제를 해결하기 위해 CURL - Contrastive Unsupervised Representations for Reinforcement Learning를 제안합니다. CURL은 self-supervised learning을 통해 data-efficiency를 높인 첫 논문임과 동시에 model-free algorithm을 통해 model-based와 model-free를 아우르는 성능을 보입니다.
- CURL는 또한 pixel-based의 다양한 RL algorithm에 적용될 수있는데, 본문의 성능비교에서는 SAC와 Rainbow DQN을 사용합니다.
Related Work
- Self-Supervised learning은 라벨링 되지않은 데이터를 통해 representation을 배우는데 주목하여 다양한 tasks에 쓰일 수 있는 learning 방법입니다.
- Contrastive Learning 는 뒤에서도 설명하겠지만, 비슷한 데이터와 비슷하지않은 데이터의 쌍을 통해 데이터의 representation을 배우는 방법입니다. 이는 query(anchor)와 비슷한 positive keys와 반대인 negative keys로 이루어져 구별하는 방식을 통해 학습합니다.
- World Models for sample-efficiency environment에 대한 model을 학습하는 방법에 대한 연구를 합니다.
Background
- on-policy, off-policy모두 쉽게 적용 가능하지만, 이 논문에서는 SAC와 Rainbow DQN을 사용하였기 때문에, 이에 대한 설명을 하지만 생략하겠습니다.
- Soft Actor Critic
- Rainbow
- Contrastive Learning
- \(q,\mathbb{K},k_+,\mathbb{K}\backslash\{k_+\}\)는 각각 anchor, target, positive, negative로 부를 수 있습니다.
-
contrastive learning에서 중요한 점은 q를 어떻게 keys \(\mathbb{K} = \{ k_0,k_1,\cdots \}\)에서 positive keys \(\{ k_+\}\)와 잘 매칭시키느냐 입니다. 그리고 이때, similarity를 표현하는 방법중에 유사도의 개념으로 가장 간단한 dot product를 사용하는데 이전 연구에서 좋은 성능을 보인 bilinear product를 사용하여 다음과 같은 InfoNCE형태의 loss로 나타냅니다.
\[\mathcal{L}_q = \log{\frac{\exp(q^TWk_+)}{\exp{(q^TWk_+)}+\sum^{K-1}_{i=0}{\exp{(q^TWk_i)}}}}\]
CURL Implementation
- Contrastive learning objective를 구체적으로 하기 위해 다음과 같은 네가지를 명확히 해야합니다.
- discrimination objective 과정
- query-key를 만들기 위한 과정
- observations을 queries,keys로 embedding하기 위한 과정
- query-key pair의 similarity를 측정하기 위한 과정
- 먼저, CURL의 architecture먼저 보고가겠습니다.
- Architectural Overview
- Input image를 frame을 쌓아 input으로 넣는 방식을 통해, spatial information외에 temporal information도 embedding하게 됩니다.
- momentum encoding을 하는데, 이는 뒤에서 설명하도록 하겠습니다.
- InfoNCE를 통해 loss를 구합니다.
- 그림을 보고 넘어가도록 하겠습니다.
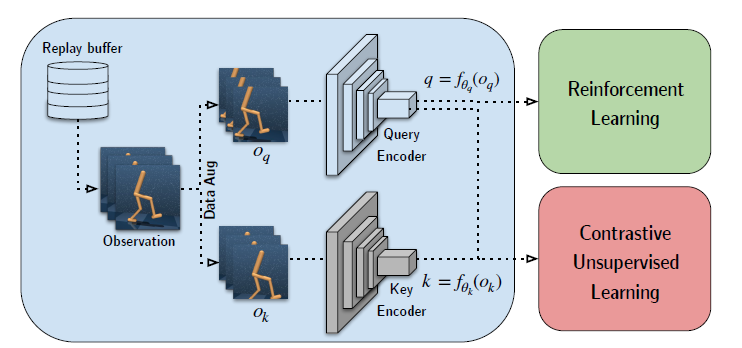
- Discrimination Objective
- Contrastive representation learning에선 어떻게 positives와 negatives를 선택할지가 중요한데, Contrastive Predictive Coding에서는 한 이미지를 쪼갠 Image patches를 이용했지만 이는 좀 더 process가 복잡해지기 때문에 적용하지 않았습니다. 이전의 연구에서도 이렇게 이미지 하나를 instance로 사용해 loss를 구한 연구가 있는데 이렇게 simple discrimination objective가 선호되는 이유에 대해 두 가지를 설명합니다.
- 첫 째로, RL은 꽤 민감한 training이기 때문에 복잡한 discrimination에 대해 agent가 수렴하지 못할 가능성이 있다는 점
- 둘 째로, Contrastive learning을 agent가 그때 그때 만드는 image를 사용하기 때문에, 연산이 가벼울수록 빠르다는 점이 있습니다.
- Query-Key Pair Generation
- CURL은 랜덤으로 crop해서 만든 image를 사용합니다.
- Similarity Measure
- bi-linear inner-product를 통해 similarity를 계산합니다.
- Target Encoding with Momentum
- key와 query encoding을 하는 network는 서로 같은 network를 쓰는게 일감으로 생각이 나지만, key network는 query network로 부터 soft update하는 형식으로 이루어집니다. 이는 이전 연구에서 network의 rapid change 때문에 수렴이 안된다고 보았기 때문입니다.
- Difference Between CURL and Prior Contrastive Methods in RL
- 기존 연구에 비해 간단하면서도 이후의 timestep을 예측하는 형태가 아닌 방식을 택합니다.
- CUR Contrastive Learning Pseudocode(Pytorch-like)
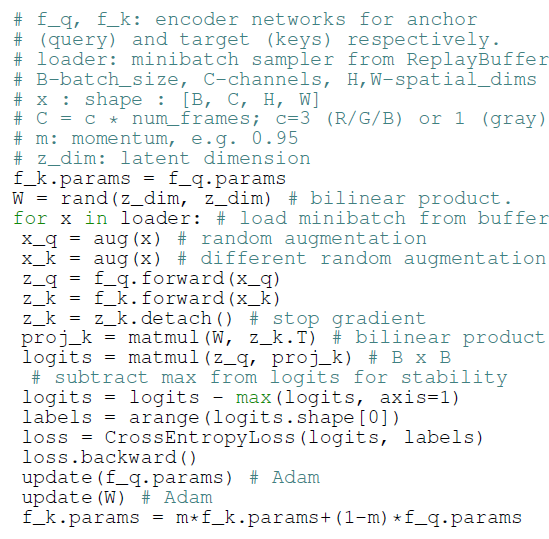
- 하나의 image가 class임을 이용해 torch.arange로 NCEloss를 구하는 과정외엔 설명할 점이 없어보입니다.
- Experiments
- 생략합니다.
- Architectural Overview