Abstract
- 최근의 연구에선 agent를 학습시킬 때, 어떤 reward에 의한 signal이 아닌 사람의 feedback을 통해 agent가 학습시키는 것을 보였고, 그런 맥락에서 연구된 COnvergent Actor-Critic by Humans(COACH) algorithm를 개선한 Deep COACH algorithm을 소개합니다.
Introduction
- RL이 다양한 분야에 적용되어가면서, reward function으로는 나타내기 어려운 복잡한 행동들에 부딪히게 되었습니다. 이 때, 이를 해결하기 위해, 사람이 직접 agent 학습도중 긍정적이거나 부정적인 feedback을 보내 학습하는 human-in-the-loop reinforcement learning(HRL)을 통해 해결법을 찾습니다.
Related Work
- 이 논문은 COACH algorithm을 발전시킨 논문으로, COACH에서 사람의 feedback이 advantage function처럼 쓸 수 있음을 보였습니다.
- HRL계열에서 TAMER라는 regression을 통해 인간의 feedback을 학습하는 방법도 존재합니다.
Approach
-
먼저 학습 과정을 간단히 보자면 다음과 같습니다.
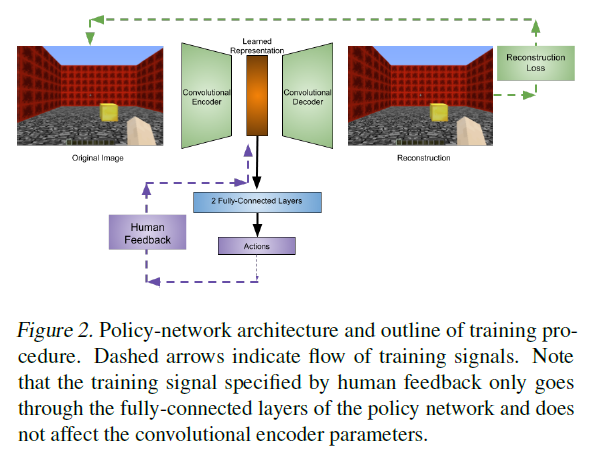
reconstruction task를 통해 pre-trained시킨 encoder 역할을 하는 network와 결합시킨 policy network는 human feedback을 통해 학습을 하게 됩니다. 알고리즘은 다음과 같습니다.

지금 보기에는 어려울 수 있지만, 적용되는 technic에 대해 하나씩 설명하도록 하겠습니다.
- Background
- agent는 environment의 reward signal을 받지 않고, 사람의 feedback \(f\)를 받게 됩니다. \(f_t \in \{ -1, 0, 1\}\)으로, \(f_t = 0\)는 feedback이 주어지지 않는 상황에 대해 얘기합니다.
- COACH
- COACH는 HRL에 속하는 Actor-Critic algorithm으로 feedback을 advantage function으로 사용합니다.
- 이 때, 사람의 feedback과 현재 action과에는 지연이 발생할 수 밖에 없으므로, 지연을 보정해주는 parameter \(d\)를 사용합니다.
- Eligibility Traces
-
모든 time-step에 있어 인간에게 feedback을 받을 수는 없습니다. 또한, feedback이 sparse하게 일어나기 때문에, 이런 상황에서 학습속도를 향상시키기 위해 eligibility trace \(e_\lambda\)를 사용합니다.
\[e_\lambda = \lambda e_\lambda + \nabla _{\theta_t} \log{\pi_{\theta_t}(a_t|s_t)} \cdots (5)\]이 때, \(e_\lambda\)는 policy gradients에 적용되기 때문에, trainable parameter와 dimension이 같습니다.
- eligibility trace의 안정적인 적용을 위해 replay buffer는 하나의 transition이 아닌 길이가 \(L\)이하이고, feedback이 0이 아닌(feedback이 주어져있는) 단위로 저장됩니다. 이는 동일확률로 선택되어 (5)와 같은 식을 계산하고 모든 minibatch의 평균을 통해 update하게 됩니다.
-
마지막으로, 이렇게 replay buffer를 이용하게되어 생기는 target과 behavior policy간의 분포의 차이를 importance sampling을 통하여 correction합니다.
\[e_\lambda = \lambda e_\lambda + \frac{\pi_{\theta_t}(a_{t'}|s_{t'})}{\pi_{\theta_{t'}}(a_{t'}|s_{t'})}\nabla_{\theta_t}\log{\pi_{\theta_t}(a_{t'}|s_{t'})}\]
- Unsupervised Pre-training
- agent network에 pixel-input을 받기 위한 cnn은 pre-train된 후엔 fix된 채로 전체 학습이 끝날 때 까지 고정되는데, 이는 Convolutional Auto-Encoder방식으로, 두 가지 network \((f_{\theta_e}, g_{\theta_d})\)로 이루어지는데, 전자는 input을 lower dimension에 encoding하고, 후자는 다시 복원하는 식으로 training됩니다. 이 loss는 다음과 같이 쓸 수 있습니다.
이 때, encoder만 agent network에서 pixel-input을 encoding하기 위해 쓰입니다.
- Entropy Regularization
- 일반적인 Actor Critic처럼 확률을 이용해 action을 sampling하지 않고, 확률이 가장 큰 action을 사용하게 되는데, 이는 feedback을 줄 때, 보다 정확하게 feedback이 가능하게 합니다. 하지만 이는, 어떤 분포를 근사할때든 마찬가지지만, 제한된 sampling이 이루어지므로, 근사시킨 분포가 너무 kurtosis가 너무 작을 수 있기 때문에, entropy term을 추가합니다.
- Deep COACH
- Eligibility trace를 사용하기 위해서라도 small network를 사용해야했지만 pre-trained한 cnn을 제외하고 policy network는 굉장히 작게 만들어졌습니다. 알고리즘과 학습과정은 위에서 설명하였습니다.