Mastering Visual Continuous Control: Improved Data-Augmented Reinforcement Learning
Abstract
- DrQ를 개선한 DrQ-v2를 소개합니다. 이는 DrQ와 마찬가지로 간단하고 쉽게 구현할 수 있지만, 이전 연구들에 비해 굉장히 큰 성능개선을 보입니다.
Introduction
- Visual(-based) Control을 해결하기 위한 주요 아이디어로 high-dimensional input을 low-dimensional representation으로 어떻게 잘 mapping하는가에 대해서 많은 연구들이 있습니다. 큰 맥락을 살피면, Auto-encoders, variational inference, contrastive learning, self-prediction, data augmentations같은 연구들이 있습니다. 그러나 아직도 model free의 SOTA method에는 세 가지 한계가 존재합니다.
- 어려운 visual control problems에 대해 아직도 해결하지 못하고 있습니다.
- 많은 양의 computational resource를 요구합니다.
- 시스템을 디자인할 때, 한 선택이 전체적인 performance에 얼마나 영향을 미치는지에 대한 점들이 모호합니다.
-
DrQ-v2는 기존의 SOTA보다 efficient면에서나, performance면에서나 굉장한 진전을 이룹니다.
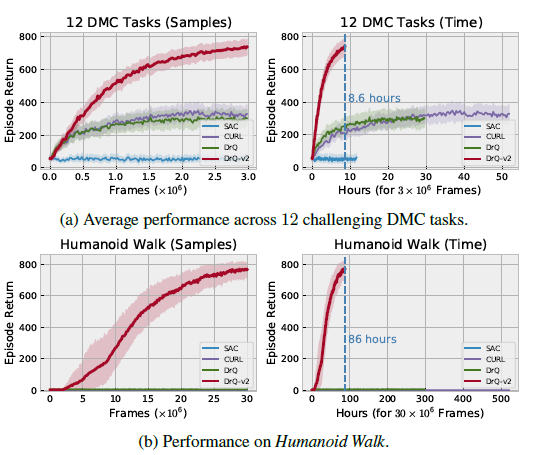
특히 그림에선 없지만 pixel-based Humanoid location problem에서 DreamerV2보다 4배 빠르게 학습해 냅니다.
- 기존의 DrQ로부터 어떤 점을 바뀌었는지 간단하게 설명하면 다음과 같습니다.
- SAC를 DDPG로 교체합니다.
- multi-step learning을 합니다.
- image augmentation시에하던 random shift에 선형 보간을 사용합니다.
- hyper-parameter를 수정합니다.
Background
- Reinforcement Learning from Image
- Deep Deterministic Policy Gradient
- Data Augmentation in Reinforcement Learning
DrQ-v2: Improved Data-Augmented Reinforcement Learning
1. Algorithmic Details
- Image Augmentation
- 기존의 DrQ와 비슷하게 boundary pixel을 복사하여 padding하긴 하지만, crop한 뒤에 선형보간을 하여 상하좌우 pixel의 평균을 사용하는 것이 성능이 더 개선되었다고 합니다.
- Image Encoder
- DrQ와 같은 encoder를 사용합니다. 이를 통해 low dimensional input으로 만드는데 이를 다음과 같이 나타낼 수 있습니다. \(\boldsymbol{h} = f_\xi(\mathrm{aug}(\boldsymbol{x}))\). 이 때 aug는 random shifts augmentation을 지칭하고, \(f_\xi\)는 encoder, \(\boldsymbol{x}\)는 observation입니다.
- Actor-Critic Algorithm
- n-step DDPG를 사용합니다. 이 때, importance sampling correction은 사용하지 않음으로써, computation과 performance사이의 균형을 맞췄습니다. 또한 clipped double Q learning과 같이 Q network를 두개 사용합니다. agent의 q network loss는 replay buffer \(\mathcal{D}\)로부터 mini-batch \(\tau = (\boldsymbol{x}_t,\boldsymbol{a}_t,r_{t:t+n-1},\boldsymbol{x}_{t+n})\)를 뽑아 다음과 같이 계산합니다.
\(\boldsymbol{h}_t = f_\xi(\mathrm{aug}(\boldsymbol{x}_t)), \boldsymbol{h}_{t+n} = f_\xi(\mathrm{aug}(\boldsymbol{x}_{t+n})), \boldsymbol{a}_{t+n} = \pi_\phi(\boldsymbol{h}_{t+n})+\epsilon\) 이고, \(\bar{\theta}_1,\bar{\theta}_2\)는 target q network입니다. 이 때, DrQ와 다른점은 target encoder에서 쓰이는 encoder도 계속 현재 \(f_\xi\)를 사용하여 embedding합니다. 그리고 action을 뽑을 때, 같은 encoder \(f_\xi\)를 사용하며, decaying \(\sigma\)에 대해 noise \(\epsilon\)을 사용하여 exploration을 합니다. 이를 나타내면 다음과 같습니다.
\[\boldsymbol{a}_t = \pi_\phi(\boldsymbol{h}_t) + \epsilon, \ \epsilon \sim \mathrm{clip}(\mathcal{N}(0,\sigma^2),-c,c)\] - Scheduled Exploration Noise
- 초반에는 exploration을 위주로, 후반은 exploitation을 위주로 하기 위해 다음과 같이 decaying \(\sigma\)를 정의합니다.
정해놓은 첫 \(\sigma_{\mathrm{init}}\)과 마지막 \(\sigma_{\mathrm{final}}\), 총 episode \(T\)에 대해 \(\sigma(t)\)는 linear하게 감소하게 됩니다.
- Key Hyper-Parameter Changes
- hyper-parameter search를 통해 기존의 DrQ보다 성능을 높일 수 있는 hyper-parameter들을 발견했습니다. 이 중 가장 중요한 hyper-parameters는 다음과 같습니다.
- replay buffer : 10배 크기의 replay buffer를 사용합니다.
- minibatch size : 기존의 512보다 작은 256의 minibatch size를 해도 성능에 지장이 없었습니다.
- learning rate : 기존의 \(1\times 10^{-3}\)보다 작은 \(1\times 10^{-4}\)의 learning rate를 사용했습니다. 이는 속도가 줄진 않았지만 좀 더 stable하게 학습할 수 있었습니다.
- hyper-parameter search를 통해 기존의 DrQ보다 성능을 높일 수 있는 hyper-parameter들을 발견했습니다. 이 중 가장 중요한 hyper-parameters는 다음과 같습니다.
- Algorithm
-
마지막으로 algorithm을 보면 다음과 같습니다.

위에서 모두 설명하였으므로 생략합니다.
-
2. Implementation Details
- Faster Image Augmentation
- DrQ에서 사용했던 kornia.augmentation.RandomCrop대신 grid_sample을 사용하여 구현하였습니다. 이는 RandomCrop이 GPU를 지원하지 않기도 하고, 선형보간을 하기 위해선 grid sample을 사용하는 것이 간편합니다.
- Faster Replay Buffer
- 기존의 replay buffer를 재구현하여서 CPU에서 GPU로 데이터를 전송하는 속도를 늘렸습니다.