Decision Transformer : Reinforcement Learning via Sequence Modeling
Abstract
- 본 논문은 기존 policy와 value network를 통해 sequential decision problem을 해결하던 것과 다르게, Transformer를 이용하여 Sequential modeling 문제를 해결하는 Decision Transformer를 제시합니다. 이는 sequence data와 Transformer를 통해 원하는 reward에 대해 auto-regressive하게 action을 만들어내게 됩니다.
Introduction
- Transformer는 정보를 high-dimensional distribution에 의미있게 모델링하는데 성공적인 적용을 보입니다. 본 논문은 이를 확장하여 sequential decision making problem에 까지 적용한 논문으로 이는 state, action, reward의 joint distribution을 modeling하고, 기존의 RL algorithm을 대체하게 됩니다.
기존의 TD learning대신 Sequence modeling objective를 통해 agent를 학습시킵니다. 둘 모두 결국 trajectory내의 Credit Assignment Problem(CAP)을 해결하기 위한 방법이라고 볼 수 있는데, Sequence modeling objective를 이용하여 얻을 수 있는 가장 큰 이점은 기존의 Deadly triad 문제를 회피할 수 있게 되었다는 점입니다. 이는 이전 해설에서 좀 더 자세하게 설명해놓았습니다. 또한 infinite horizon MDP를 가정하였기에 도입한 discount factor를 제외시켜 근시안적인 행동을 유발할 수 있는 요소를 제거합니다.
Transformer는 self-attention을 통해 CAP를 해결합니다. 기존 Bellman backup이 가지는 문제를 좀더 쉽게 해결할 수 있고 이는 reward가 sparse할 수록 더 효과적입니다.
본문의 experiments는 offline RL에 집중합니다. 이는 error propagation과 value overstimation이 대표적인 문제로 손꼽아지고 이런 문제들에 효과적임을 보이기 위해 적절한 선택이라고 생각합니다. 반대로 exploration을 어떤식으로 적용해야할지가 future work정도로 보입니다. agent는 reward를 query로써 action을 얻게됩니다.
Illustrative example
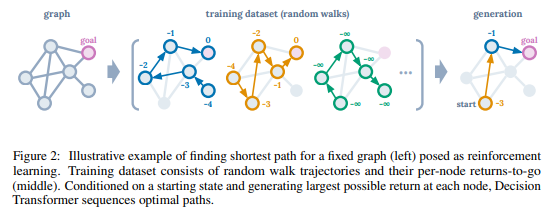
- Decision Transformer의 발상에 대해 설명합니다. 아래 그림과 같이 shortest path를 찾는 문제에서부터 시작합니다. 본문은 Offline learning을 통해 random walk trajectories를 학습하는 상황에 대해 설명하는데, 이는 미래에 받을 reward에 대해서 다음 action을 예측하는 식으로 optimize하도록 학습됩니다. 이 때, dynamic programming없이 policy improvement를 보이게 됩니다.
Preliminaries
Offline Reinforcement Learning
- Offline RL은 environment와 상호작용하여 data를 얻는 것이 아닌, 정해진 dataset을 가지고 policy를 학습합니다. 이는 environment로부터 feedback을 받는 것이 불가능하므로 exploration이 어려움을 의미합니다.
Transformers
- Transformer는 Sequential data에서 효과적인 모습을 많이 보였습니다. 이 때 self-attention layer는 residual connection을 통해 구성되어 있습니다. 각 layer는 n개의 input에 대한 embedding을 받습니다. 이 때 각 token은 key, query, value로 mapping됩니다. \(z_i=\sum^n_{j=1}\mathrm{softmax}(\{ \langle q_i,k_{j'}\rangle \}^n_{j'=1})_j \cdot v_j\) 이 때, 당연하게도 summation/softmax는 이전의 action까지로 제한됩니다.
Method
- 이번 section에서는 Decision Transformer에 대해 어떻게 작동하는지에 대해 설명합니다.
Trajectory representation
-
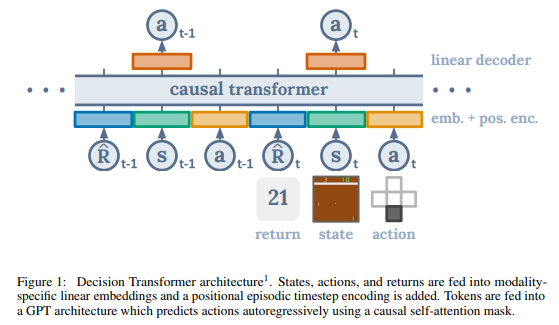
Trajectory representation에서 가장 중요한 것은 transformer가 얼마나 의미있는 pattern을 학습가능한지와 이를 이용해 test 때, action을 생성할 수 있어야합니다. 이를 위해, reward를 어떻게 넣는 것이 합리적인가에 대해 생각해보아야 하고, 이를 이후에 받을 reward의 합(return-to-go) \(\hat{R}_t = \sum^T_{t'=t}r_{t'}\)로 정의합니다. 이를 나타내면 다음과 같습니다.
\[\tau = (\hat{R}_1,s_1,a_1,\hat{R}_2,s_2,a_2,...,\hat{R}_T,s_T,a_T)\]test때엔 원하는 performance(reward에 따라 action이 결정되므로)와 starting state에 대해 initialize합니다.
Architecture
- 마지막(최근) K-step의 trajectory를 Decision Transformer의 input으로 받습니다. 이 때 각 modality마다 state, action, reward를 embedding하고 normalization합니다. 또한 time step도 embedding하여 각 embedding시킨 값에 더해지게 됩니다.
Training
-
offline dataset으로부터 K-length의 minibatch를 뽑습니다. training과 evaluate은 아래와 같은 algorithm으로 이루어집니다. 이 때, loss는 continuous action일 때, mean-squared error, discrete할 때, cross entropy를 사용합니다.
